In the fields of HPC and AI, the demand for efficient and scalable storage solutions is ever-increasing. Traditional storage systems often struggle to meet the high throughput and low latency requirements of modern AI workloads. Disaggregated storage, particularly when combined with NFSoRDMA, presents a promising solution to these challenges. This blog post will explore the objectives, performance requirements, and solutions for implementing disaggregated storage tailored for AI workloads.
NFSoRDMA combines the widely adopted NFS protocol with the high-performance RDMA technology. By using standard protocols and avoiding proprietary software, we can sidestep limitations in OS compatibility and version conflicts. NFSoRDMA allows to achieve the required performance levels with minimal deployment costs, without the need for specific compatibility lists for parallel file system clients or strict version compatibility for all components. We maximize the utilization of a 400Gbit interface, demonstrating that high performance can be achieved efficiently. This integration ensures low latency and high throughput, making it ideal for our demanding storage needs.
Objectives
AI workloads often demand more than just a block device. They require sophisticated file storage systems capable of handling high performance and scalability needs. Our primary objectives in developing disaggregated storage solutions include:
- Achieving High Throughput: The goal is to reach dozens of GBps from a few clients using one or two storage nodes, whether real or virtual.
- Maximizing IOPS: It's crucial to obtain as many small IOPS as possible to support the high-speed data processing needs of AI tasks.
- Simplicity in Configuration: Keeping both hardware and software configurations as straightforward as possible is essential for ease of deployment and maintenance.
- Deployment Flexibility: The solution must be deployable on-premise or in the cloud, offering on-demand scalability and flexibility.
AI tasks often necessitate parallel access to data from multiple clients at speeds of tens to hundreds of gigabytes per second. Our software solutions aim to minimize complexity while ensuring high performance and scalability.
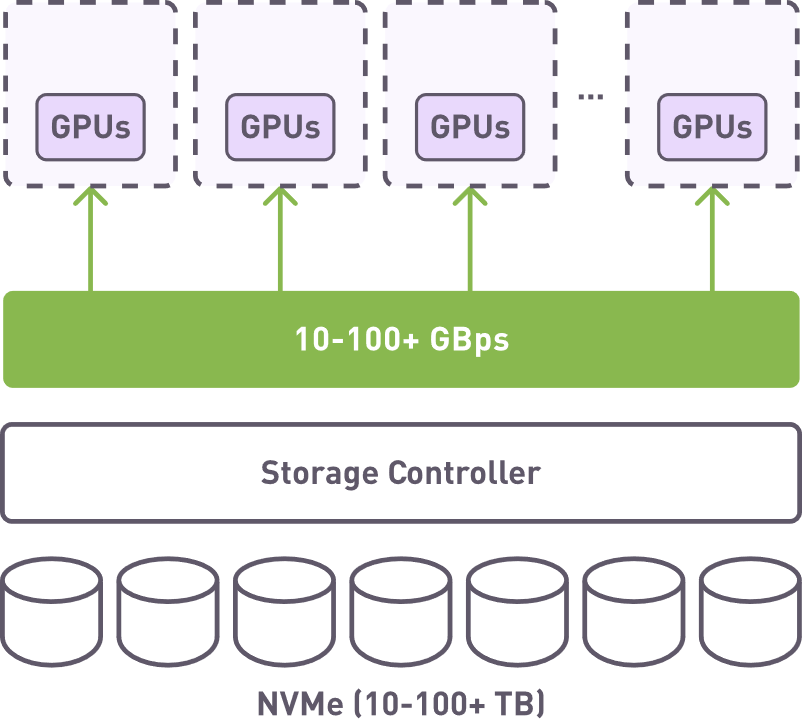
Required disaggregated storage solution
Performance Requirements
For efficient cluster operations, it is essential to have fast data loading and quick checkpoint writing. These requirements are critical for maintaining high performance in AI and HPC environments.
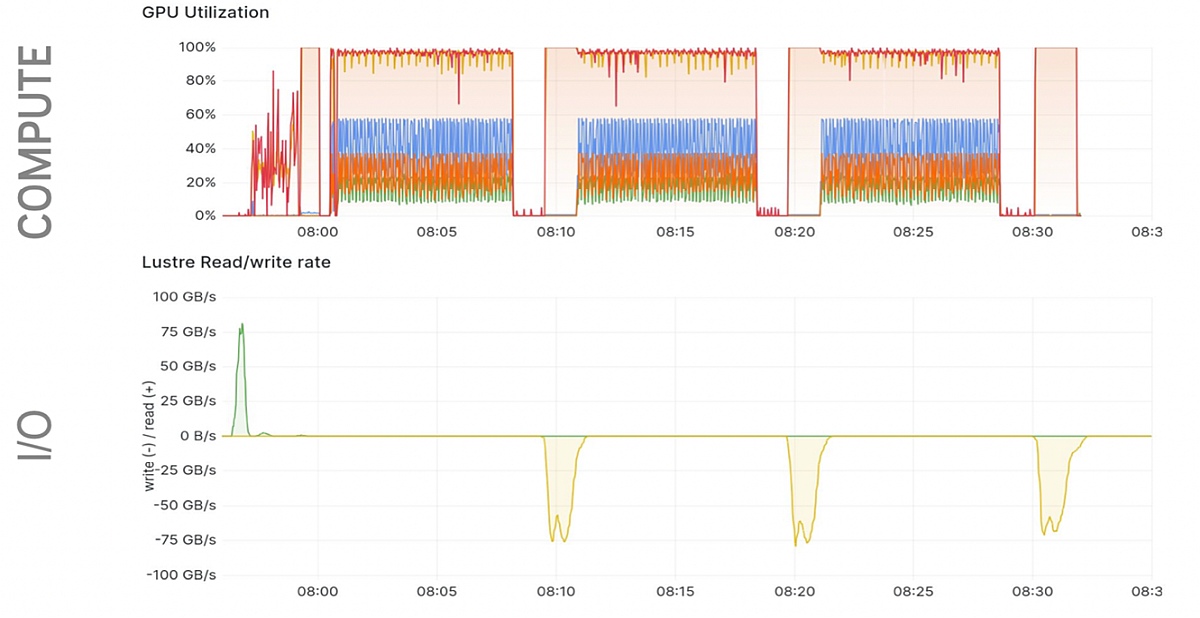
More details here: IO for Large Language Models and Secured AI Workflows
The provided graph above illustrates GPU utilization and Lustre read/write rates during an iterative processing cycle, common in HPC workloads. Initially, there's a brief period where the GPU utilization ramps up, known as the startup phase. This is followed by sequences of compute iterations, where GPU utilization remains high, indicating active processing. Periodically, there are drops in GPU utilization, corresponding to checkpointing phases where data is saved. During these phases, the GPUs are mostly idle, waiting for the checkpoint to complete.
The Lustre read/write rates reflect this workflow with distinct phases. At the beginning, there's a significant spike in read activity during the initialization phase as the system loads initial data, which occurs only once. During compute iterations, read activity is minimal, reflecting the workload's focus on computation rather than data movement. Every few compute iterations, checkpointing occurs, causing spikes in write activity. During these phases, data is written to storage, and GPU computation is paused.
Although this example is based on data from an NVIDIA presentation focused on Lustre, the underlying principles are also applicable to NFS systems. The current pattern reveals opportunities for efficiency improvements. For example, implementing parallel or asynchronous checkpointing could significantly reduce the idle time of GPUs during checkpointing phases. Our solution aims to address these inefficiencies, providing a more streamlined and effective process for handling high-throughput storage demands in HPC and AI workloads.
High-Level Solution Description
Our solution integrates a high-performance storage engine with well-known filesystem services, focusing on:
- Software-defined RAID: Deployable across various environments such as bare-metal, virtual machines, and DPUs.
- Tuned Filesystem (FS) and Optimized Server Configuration: Ensures optimal performance and efficiency.
- RDMA-based Interfaces for Data Access: Provides the high-speed data access required for AI workloads.
The main idea is to deploy different elements of the file storage system on-demand across the necessary hosts. Disaggregated storage resources are combined into virtual RAID using xiRAID Opus RAID engine, which requires minimal CPU cores. Volumes are then created and exported to virtual machines via VHOST controllers or NVMe-oF, offering flexible and scalable storage solutions.
We will explore the virtualization of NFSoRDMA and xiRAID Opus, observing the limitations in the Linux kernel space and explaining how our solution can be virtualized.
To validate our solution, we will utilize FIO (Flexible I/O Tester) to conduct two types of tests: sequential reads/writes to demonstrate data load and checkpoints performance, and random reads to demonstrate small data reads performance. FIO allows us to utilize various engines and regulate the load, ensuring simplicity and repeatability.
Introducing Virtualized NFSoRDMA + xiRAID Opus Solution
New virtual storage systems comprise two critical components: a high-performance engine running in user space and virtual machines that act as NAS gateways, instantiated on demand. This architecture allows efficient allocation of storage resources, balancing high performance with the scalability and flexibility required in virtualized environments.
We deployed on-demand storage controllers and built virtual storage volumes for tenants from disaggregated storage resources. Deploying on-demand storage controllers and constructing virtual storage volumes from disaggregated storage resources offers each tenant its own dedicated virtual storage. This approach leverages two key components: xiRAID Opus, a high-performance block volume, and an NFS gateway. xiRAID Opus provides RAID-protected block devices tailored for virtualized environments, ensuring robust performance and reliability.
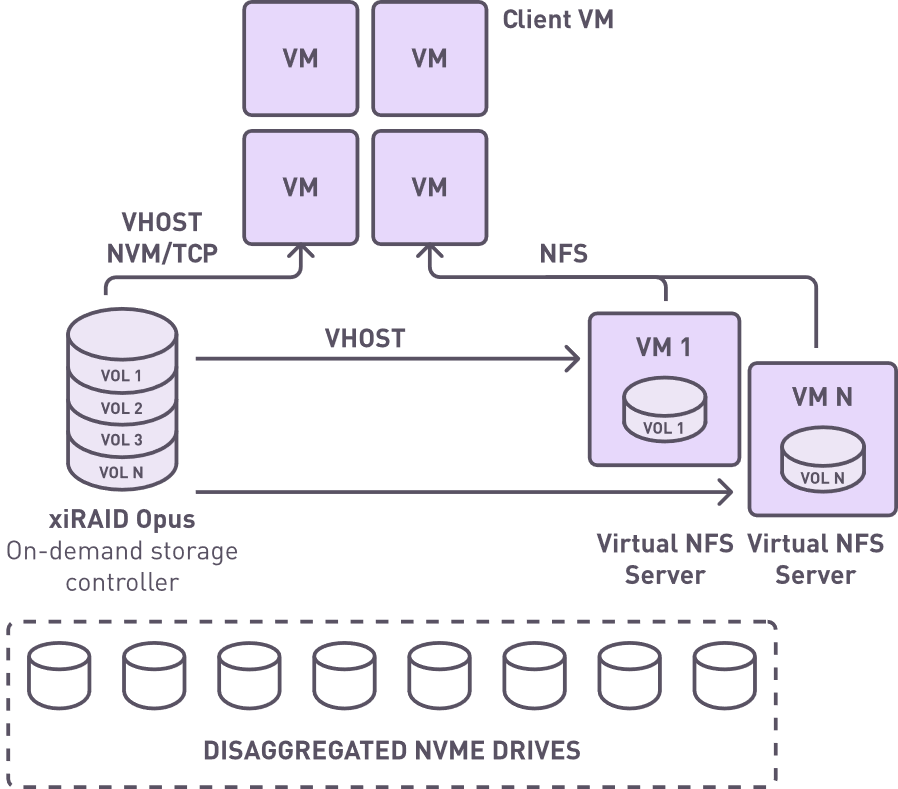
Virtualized solution architecture with on-demand storage controllers
However, performance remains a significant challenge in virtual environments, worsened by hardware and software limitations such as below:
- PCI slot taxation by accelerators: This issue is particularly critical in cloud environments than in bare metal installations.
- Linux kernel updates and live patching: Frequent in virtualized settings, these updates can destabilize proprietary software reliant on specific kernel versions.
- Vhost protocol implementation: Limited to 250K IOPS per volume in the kernel, this constraint consumes significant resources, hindering overall efficiency.
To overcome these challenges, our solution operates the block device engine efficiently, using just 2-4 CPU cores while providing access to high-performance virtual block devices.
Key Features of Our Virtualized Solution
Our virtualized storage solution includes:
- Software RAID controller in User Space
- Volume manager with QoS Support
- Multi-threaded VHOST in User Space
- SR_IOV to pass NIC functions into VM
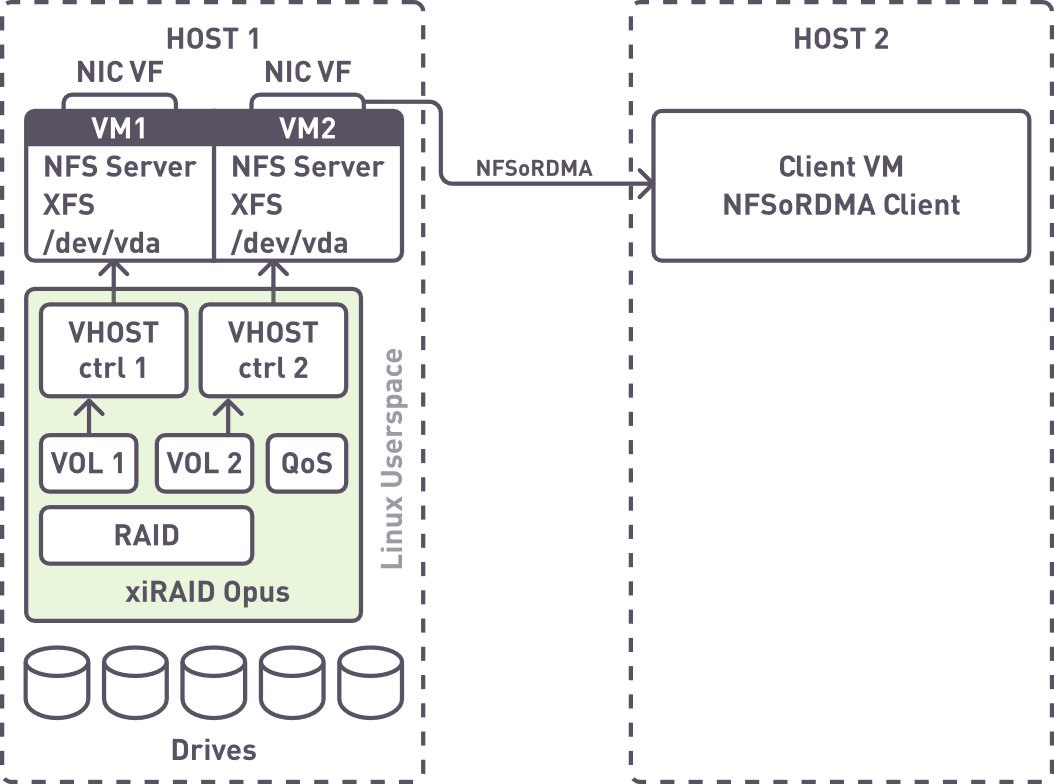
Our virtualized solution architecture
By aggregating namespaces into virtual arrays and creating volumes with specific size and performance characteristics, we pass these devices into virtual machines. These VMs function as virtual NVMe over RDMA servers, connected to high-performance network cards, either on the same or remote hosts, and client VMs can connect directly or through a host using virtio-fs.
The data path in our solution, while complex, is optimized by reducing levels and enhancing the efficiency of each. This optimization maintains compatibility with existing solutions, while reinventing or improving key components (highlighted in color) to achieve greater efficiency.
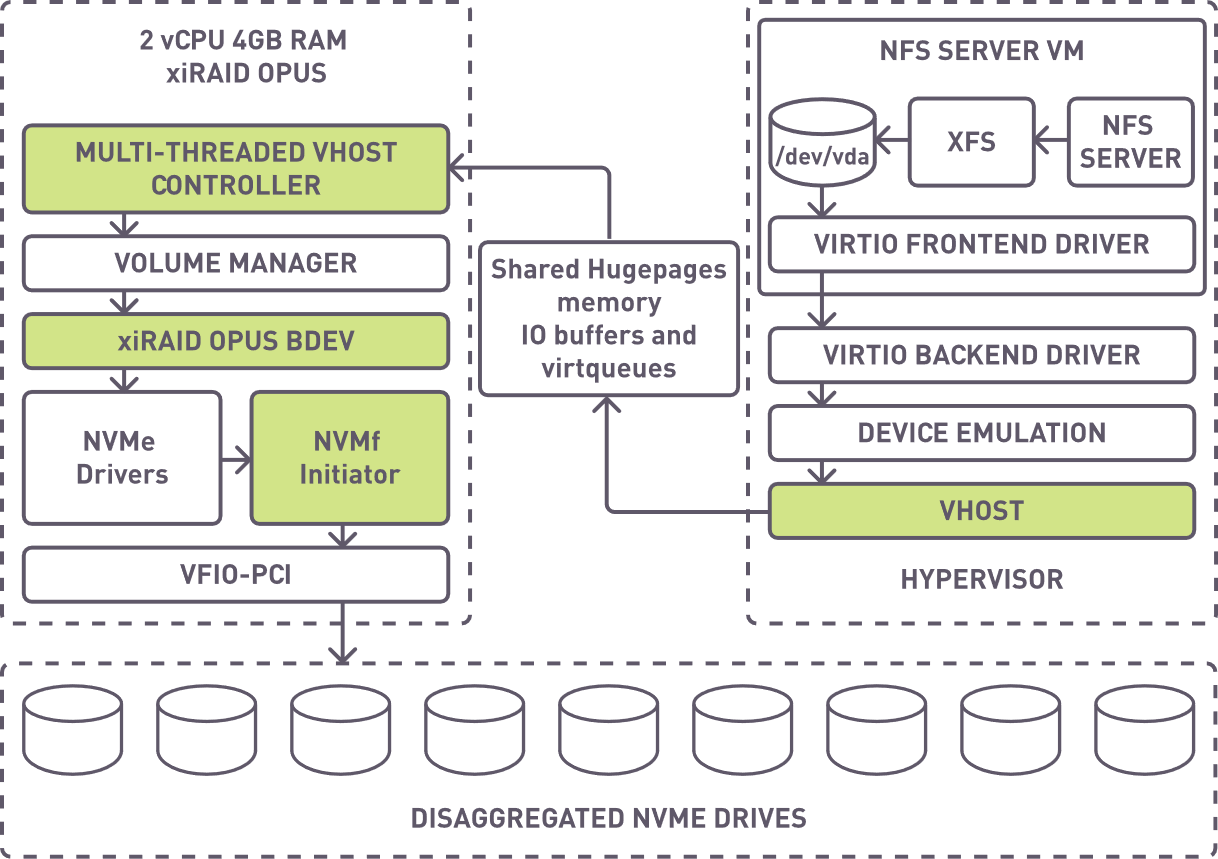
Data flow design
Testing Configuration
- Only two CPU cores for RAID and vhost controller
- 24 CPU cores for NFS SERVER VM
- RAID 50 (8+1) x2
- KIOXIA CM6-R drives
- AMD EPYC 7702P
- Filesystem is aligned with RAID
We created one volume, passed it into a single VM, and applied load from two virtual clients on a remote host to evaluate performance.
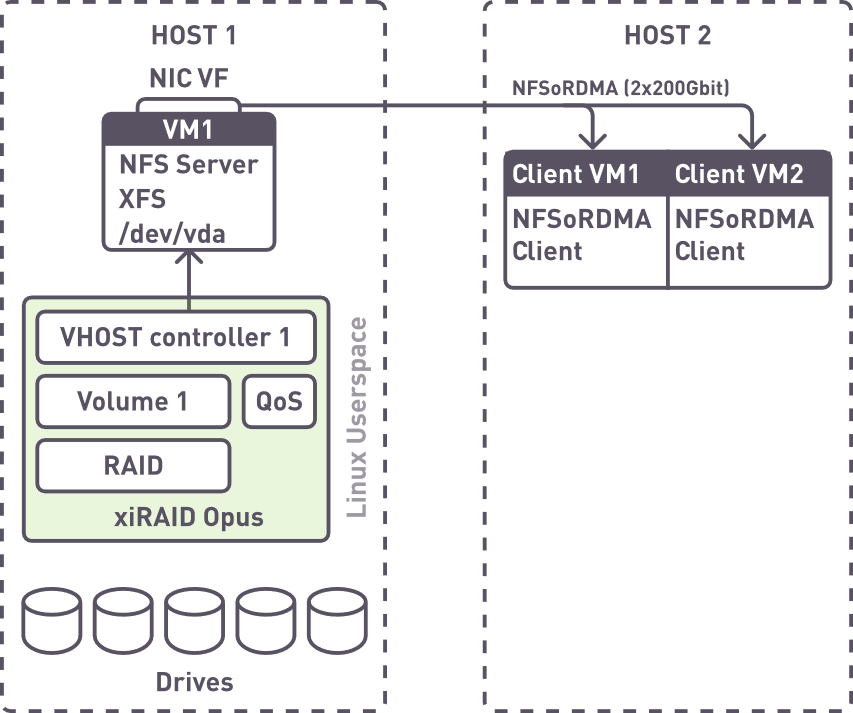
Test architecture
Testing Results
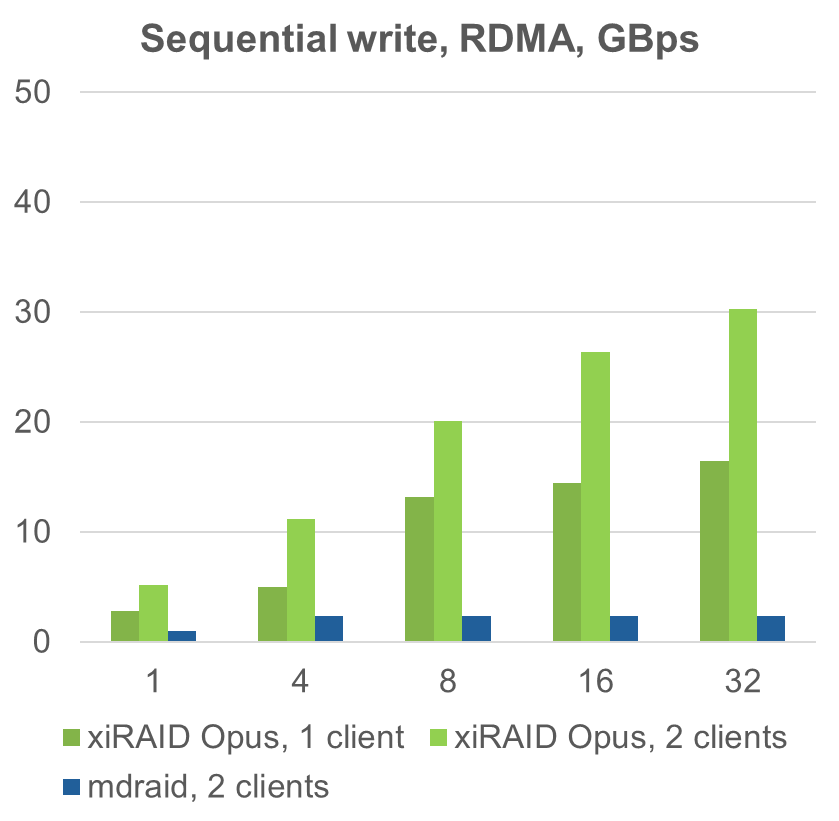
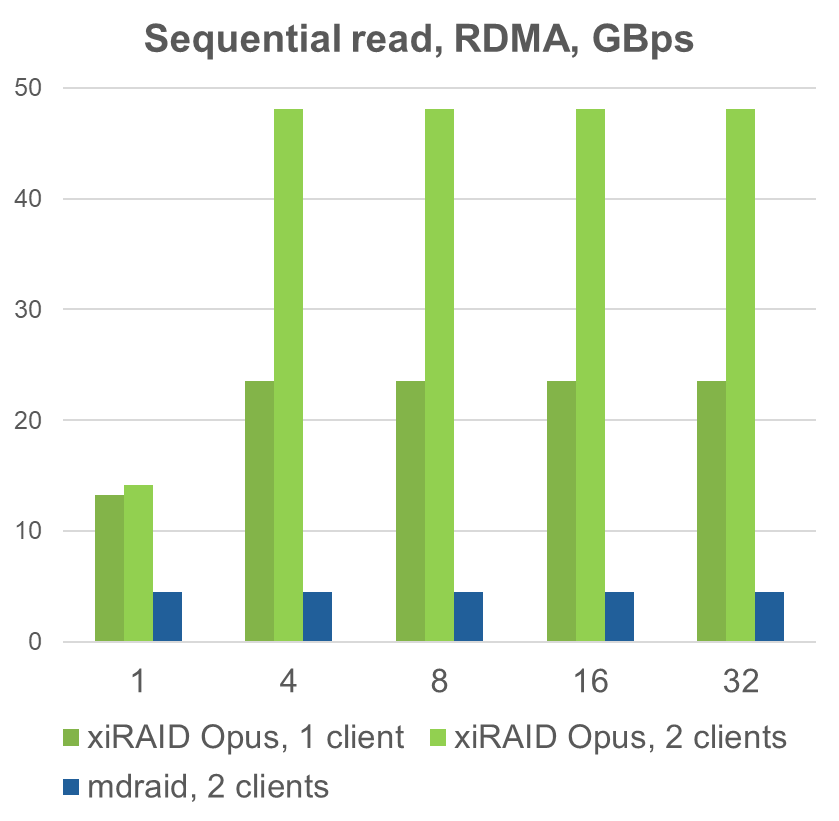
In performance comparisons for sequential operations, mdraid shows significant performance losses, up to 50%, whereas xiRAID Opus maximizes interface read performance, achieving approximately 60% of the interface's potential for writes with one or two clients. This highlights xiRAID Opus's superior performance in virtualized environments.
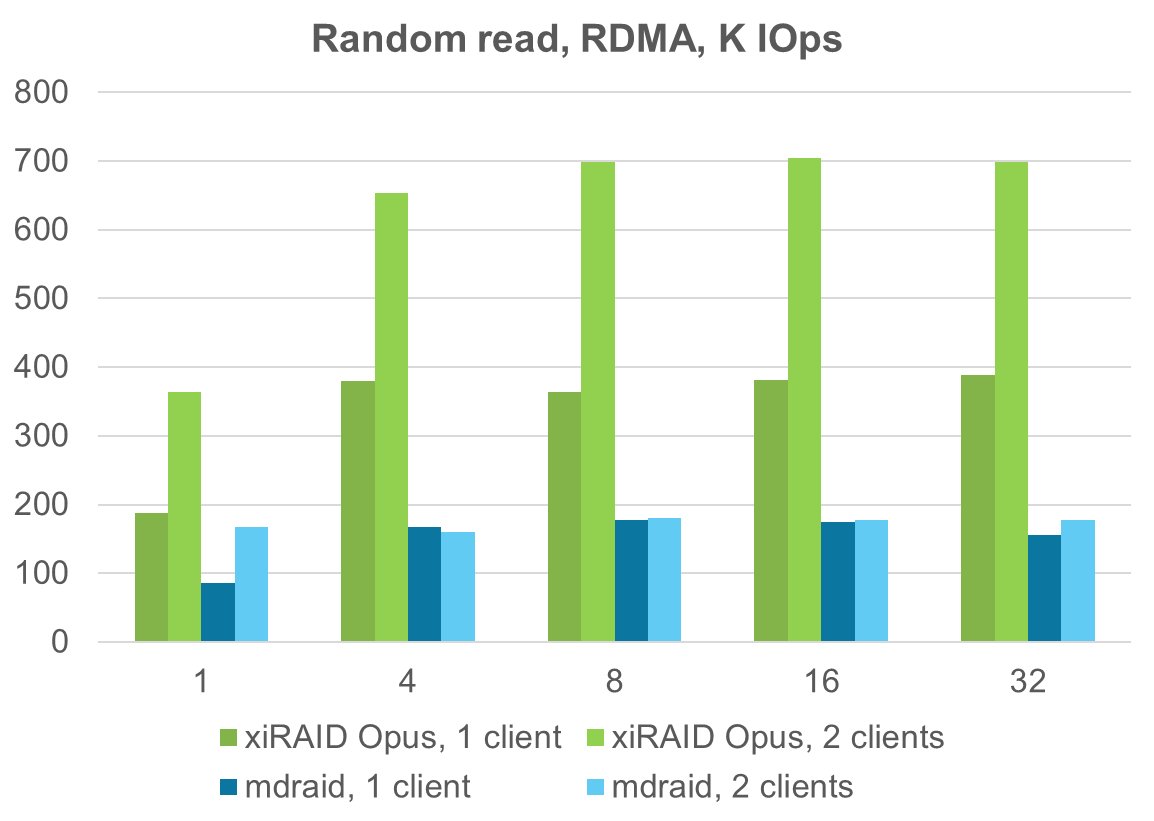
In random read operations, when using 2 clients, xiRAID Opus shows superior scalability and a significant increase in performance, reaching up to 850k-950k IOPS. In contrast, mdraid-based solutions failed to scale effectively, demonstrating kernel limitations that cap small block read performance at 200-250k IOPS per VM. Our user-space solution nearly approaches 1 million IOPS after connecting 3 clients, further highlighting the scalability and efficiency of xiRAID Opus over mdraid.
When comparing CPU load, mdraid combined with kernel vhost and a virtual machine utilizes nearly 100% of about a quarter of the CPU cores. Conversely, xiRAID Opus uses only two fully loaded cores, with around 12% of the remaining cores operating at approximately 25% load.
MDRAID + NFS virtual machine:

¼ of all CPU cores are fully loaded
xiRAID Opus + NFS virtual machine:

Only 2 CPU cores are fully loaded
Wrap-Up and Final Thoughts
The following conclusions highlight the significant efficiencies observed in our virtualization of NFSoRDMA and xiRAID Opus:
- A single virtual NFS server can saturate a 2x200 Gbit interface, performing comparably to a large server.
- xiRAID Opus storage engine requires only 2 CPU cores, whereas mdraid consumes much more CPU.
- mdraid is limited both in sequential and random operations.
- By virtualizing our solutions, we achieve around 60% efficiency for write operations and 100% efficiency for read operations.
NFS over RDMA combined with xiRAID enables the creation of fast storage nodes, providing 50 GBps performance and saturating a 400 Gbit network. This is ideal to provide fast storage to NVIDIA DGX systems at universities and large research institutions. The main ingredients for such solution are the storage engine, NFS server, and client tuning.
Achieving high performance in virtual environment proves to be possible. While Linux kernel presents performance limitations, the user space-based RAID engine is the solution. It reduces resource consumption while maintaining performance, comparable to bare-metal installations. Our extensive testing and implementation of disaggregated storage based on NFSoRDMA highlight significant advancements in performance and efficiency for AI workloads.
Appendix
NFS Settings
Server Side:
nfs.conf
threads=32
[nfsd]
# debug=0
threads=32
rdma=y
rdma-port=20049
/etc/exports
/data *(rw,no_root_squash,sync,insecure)
Client Side:
MDRAID tuning
mdadm –-grow /dev/mdX bitmap=none #gives 13GBps write but not recommended in real env
mdadm –-grow /dev/mdX --bitmap=internal --bitmap-chunk=524288. #gives 7,5 GBps write
ZFS settings
zfs_vdev_sync_{read/write}
zfs_vdev_async_write_max_active=64
Fio config
bs=1M
iodepth=32
direct=1
ioengine=libaio
rw=read/write
size=100G
[dir]
directory=/test
[global]
bs=4k
iodepth=128
direct=1
ioengine=libaio
rw=randread
size=100G
norandommap
[dir]
directory=/test