Boosting virtual machine performance in Proxmox environments has always been a challenge due to inherent limitations in the existing I/O architecture. Xinnor's latest solution xiRAID Opus, a software RAID engine operating in user space, addresses this issue head-on.
Extensive experiments, conducted by Xinnor and Kioxia, have demonstrated significant performance limitations in Linux kernel-based solutions. Virtual machines are typically limited to a maximum of 308K IOPS for read operations, which is insufficient for many modern applications that require substantially higher performance. The disparity in random write performance between kernel-based solutions and bare-metal solutions is even more pronounced.
Performance further deteriorates in degraded mode, consuming more resources and severely impacting application performance. Our blog post on PostgreSQL database performance provides a detailed comparison, showing that for simple update operations, kernel-based mdraid performs 5 times slower than xiRAID Opus. In degraded mode, mdraid performance drops to 25 times slower than xiRAID Opus. These limitations make it inefficient to virtualize resource-intensive applications in environments like Proxmox using traditional methods. A common workaround involves passing multiple independent block devices into a virtual machine, which are then combined or used directly by the application. However, this approach increases management complexity, raises the probability of configuration errors, and cannot be considered truly efficient.
Our goal is to demonstrate that it's now possible to provide a single, high-performance volume to a virtual machine. This volume can be utilized by the most demanding applications, offering simplified management, reduced risk of configuration errors, and improved overall efficiency. This approach allows for effective virtualization of resource-intensive applications, overcoming the limitations of traditional kernel-based solutions and supporting high-performance applications within virtual environments.
Challenges in Proxmox Virtual Environment
In traditional Proxmox configurations, the virtio paravirtualization driver (virtio-blk, virtio-scsi, virtio-net) is commonly used to connect drives to virtual machines. However, a significant performance bottleneck exists due to the limitation of a single iothread handling the entire I/O stream for each attached drive (e.g. LVM thin volume). This restriction considerably impacts the performance of virtual machines, as increasing I/O throughput necessitates either the addition of more drives or the deployment of additional virtual machines — solutions that are often impractical for end-user applications.
Recognizing this challenge, Xinnor has developed a solution designed to overcome the performance limitations inherent in this kernel-space setup. Our approach leverages high-performance volumes that seamlessly integrate with Proxmox without replacing the standard storage options.
By utilizing the vhost interface, these volumes are exported to virtual machines through a host-based process capable of exposing virtualized block devices to QEMU instances or other processes. This innovation significantly enhances storage performance and reduces latency, ensuring that even the most demanding applications can operate efficiently within Proxmox environments.
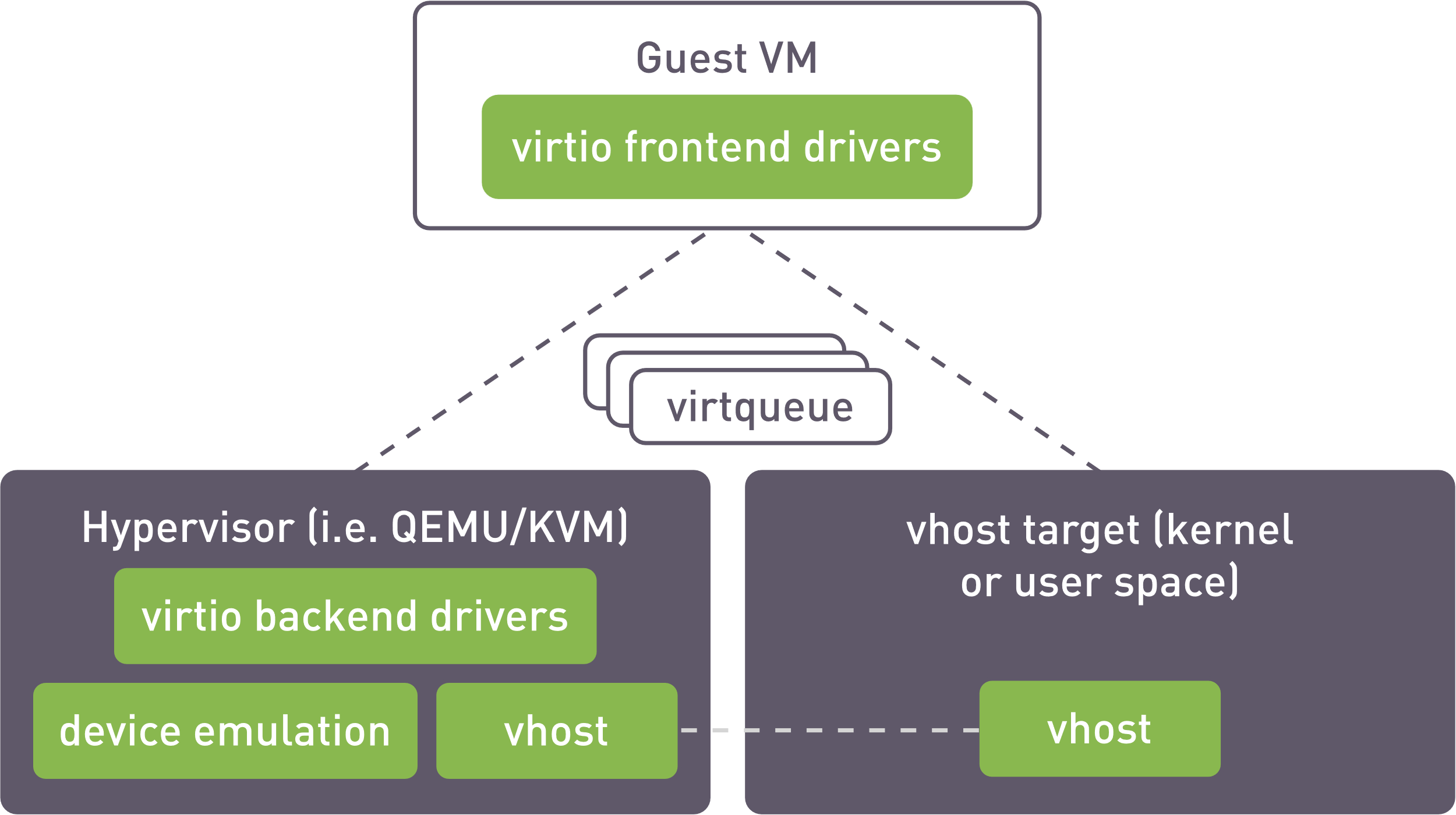
vhost operation scheme
We’ve run 2 experiments to test the following:
- Theoretical performance of 1 virtual machine with resources given to one vhost-target.
- Performance scalability across a range of 1 to 8 virtual machines connected to vhost-targets.
These experiments aim to validate the performance gains and scalability improvements offered by our solution in Proxmox environments.
About Proxmox VE
Proxmox Virtual Environment is a complete, open-source server management platform for enterprise virtualization. It tightly integrates the KVM hypervisor and Linux Containers (LXC), software-defined storage, and networking functionality, on a single platform. With its integrated web-based user interface you can manage VMs and containers, high availability for clusters, or the integrated disaster recovery tools with ease.
About xiRAID Opus
The xiRAID Opus software implements a storage system using a user-space data path engine and management components. The user-space engine enables the system to achieve high speeds and eliminates dependencies on the operating system version, drivers, and libraries.
The xiRAID engine is a high-performance software RAID system, leveraging multiple components to optimize performance. One key component is the internal userspace high-performance hardware drivers, facilitating efficient IO operations with local or network-connected devices. By bypassing the OS drivers, xiRAID interfaces directly with the hardware storage devices. To use a device with the storage engine, it must be detached from the operating system and attached to the xiRAID engine for visibility. Once attached, the device is managed exclusively by xiRAID and is no longer accessible in the host OS. Upon restart, xiRAID automatically re-attaches previously connected storage devices.
Additional information about xiRAID Opus can be found here:
https://xinnor.io/
Testing environment
- Platform: Supermicro server AS-2125HS-TNR
- CPU: 2х Genoa 9454 DP/UP 48C/96T 2.75G 256M 290W SP5
- RAM: 256GB DDR5 Memory
- Drives Subsystem: 10 x Micron_9400_MTFDKCC7T6TGH
- Proxmox version: proxmox-ve: 8.2.0 (running kernel: 6.8.8-1-pve)
- xiRAID Opus Version: 1.0.1
- RAID configuration: RAID 6 with 10 drives ss=128 bs=4096
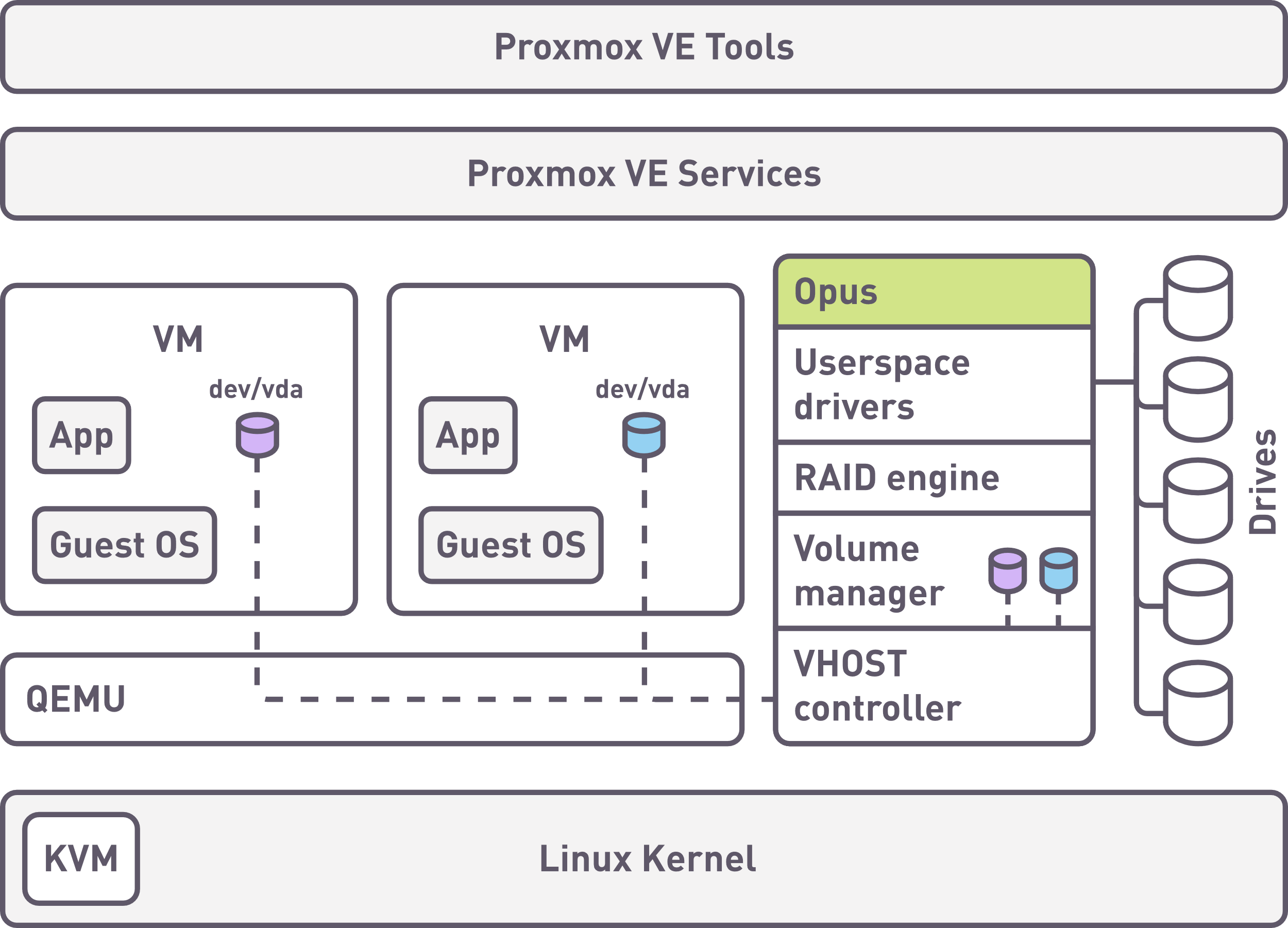
Test stand architecture
Storage subsystem backend performance
To obtain basic values of the disc subsystem performance and to make sure that there are no bottlenecks on particular hardware, we perform backend measurements with fio-3.33.
The result of measurements is presented in the table below, the link to the configs can be found in the appendix. As you can see from the table, the drive's performance is close to the performance declared by the manufacturer.
| Number of drives | Backend pattern (number of jobs/queue depth) | Backend performance |
|---|---|---|
| 1 | Sequential write (1/32) | 7.09 GB/s |
| Sequential read (1/32) | 7.26 GB/s | |
| Random write (2/128) | 0.38M IOPS | |
| Random read (2/256) | 1.5M IOPS | |
| 10 | Sequential write (1/32) | 69.3 GB/s |
| Sequential read (1/32) | 72.5 GB/s | |
| Random write (2/128) | 3.66M IOPS | |
| Random read (10/256) | 16M IOPS |
Proxmox and xiRAID Opus configuration
For testing, we used a RAID 6 with 10 drives with a 128kb strip size created in user space. In case of testing scalability of 8 virtual machines performance, RAID was divided into 8 partitions to distribute the RAID resources among virtual machines. A vhost-target was created on each partition. Each vhost-target was allocated 2 cores in polling mode from the subset of 16 allocated xiRAID Opus cores.
In case of testing 1 virtual machine, 1 vhost-target was created for the entire RAID volume and all 16 cores were allocated to this vhost-target.
Proxmox was installed with default parameters.
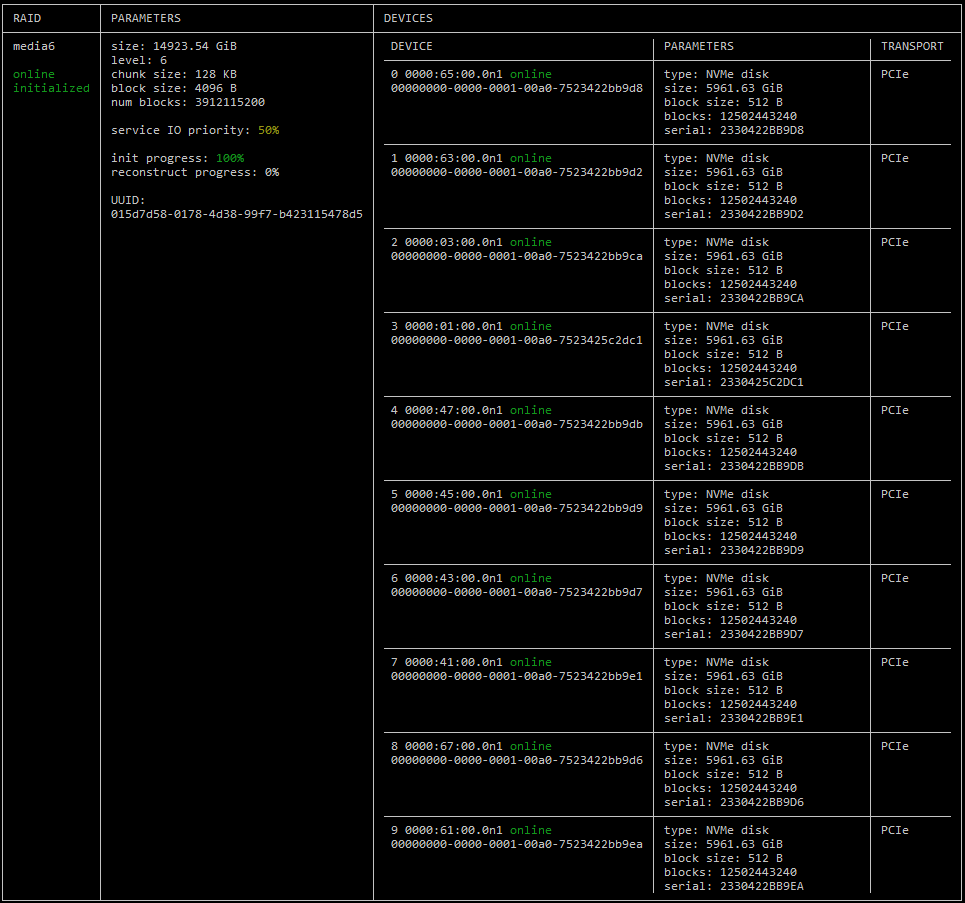
The output of the RAID configuration parameters
Installation and configuration steps
Below is an example of the steps to configure xiRAID Opus and virtual machines to test the scaling of I/O operations on 8 virtual machines.
For the tests on one virtual machine, we skipped point 4 with partitioning and created 1 vhost with CPU bitmask 0xFFFFFFFF.
1. Download and install xiRAID Opus
cd ver1.0.0-b
sudo ./install.sh -m 0xFFFF --hugemem 65536
sudo systemctl start xnr_xiraid
xnr_cli license show
Download xiRAID Opus and install it according to the instruction: https://xinnor.io/resources/xiraid-opus/. 0xFFFF means 16 cores allocation for xiRAID Opus and 64 GB RAM.
2. Prepare the drives
xnr_cli drive-manager attach --ids xnr_cli drive-manager attach --ids 0000:65:00.0,
xnr_cli bdev show | grep 0n1
xnr_cli bdev zero --bdevs 0000:65:00.0n1,
Connecting the drives to xiRAID Opus user space.
3. Create RAID
Creating RAID6 named “media6”, chunk size equals 128, block size equals 4096.
4. Creating partitions
RAID was split into 8 partitions, -s describes the partition size in MB.
5. Creating vhost device for each partition
xnr_cli vhost show | grep vhost
vhost target is created for each partition (media5p0, media6p0, media6p1, media6p2, media6p3, media6p4, media6p5, media6p6, media6p7). 2 CPU cores allocated for each vhost target.
To achieve high performance, we assign a specific CPU mask to each controller. It is preferable that these CPU masks for different controllers do not overlap. This approach ensures optimal resource allocation and helps prevent performance bottlenecks.
6. Connecting partitions to VMs
At this stage, you need to edit the virtual machine configuration file. This is done using a text editor, not through the Proxmox UI, as there isn't currently an option to connect vhost-targets directly from the interface.
Edit the VM configuration file. For example, if your VM ID is 100:
Add the following arguments to the file:
Argument breakdown:
- Memory backend specification: -object memory-backend-file,id=mem,
size=8192M,mem-path= This specifies the shared memory for the VM. QEMU must share the VM's memory with the SPDK vhost target./dev/hugepages,share=on -numa node,memdev=mem - Vhost-BLK device addition: -chardev socket,id=char1,path=
/opt/xiraid/bin/ This adds the Vhost-BLK device to the VM.xnr_conf/sock/vhost.X -device vhost-user-blk-pci, id=blk0,chardev=char1
Important notes:
- The size option must match the amount of memory dedicated to the VM.
- Each VM will have its own vhost controller with a unique name.
- Replace vhost.X with the number of the vhost controller you created for this specific VM.
- Ensure you use the correct vhost controller number for each VM to avoid configuration errors.
- After configuration, vhosts will be available in VMs as block devices: /dev/vda
Testing Linux Virtual Machines
Testing full capacity of 1 VM
Performance testing was performed from virtual machines using fio-3.36.
Virtual machine configuration:
- Ubuntu 24.04 LTS (6.8.0-35-generic)
- CPU cores: 16
- RAM: 16384 MB
fio read/write config:
bs=1M
direct=1
iodepth=32
numjobs=8
group_reporting
rw=read
#rw=write
ioengine=libaio
runtime=600
offset_increment=12%
[vda]
filename=/dev/vda
fio random read/write config:
bs=4k
direct=1
numjobs=32 #different number of jobs
iodepth=32 #different number of iodepth
norandommap=1
group_reporting
rw=randread
random_generator=lfsr
ioengine=io_uring
hipri=1
fixedbufs=1
registerfiles=1
runtime=60
[vda]
filename=/dev/vda
Results
This document uses the following baseline performance metrics, based on a 10-drive backend configuration:
- Random read: 100% of raw backend performance (16M IOPS)
- Sequential read: 100% of raw backend performance (72.5 GB/s)
- Random write: 33% of raw backend performance (1.22M IOPS). Calculation: 3.66M IOPS x 33% = 1.22M IOPS
- Sequential write: 80% of raw backend performance (55.4 GB/s). Calculation: 69.3 GB/s x 80% = 55.4 GB/s
The reduced write performance percentages (33% for random and 80% for sequential) reflect the overhead introduced by the RAID6 configuration.
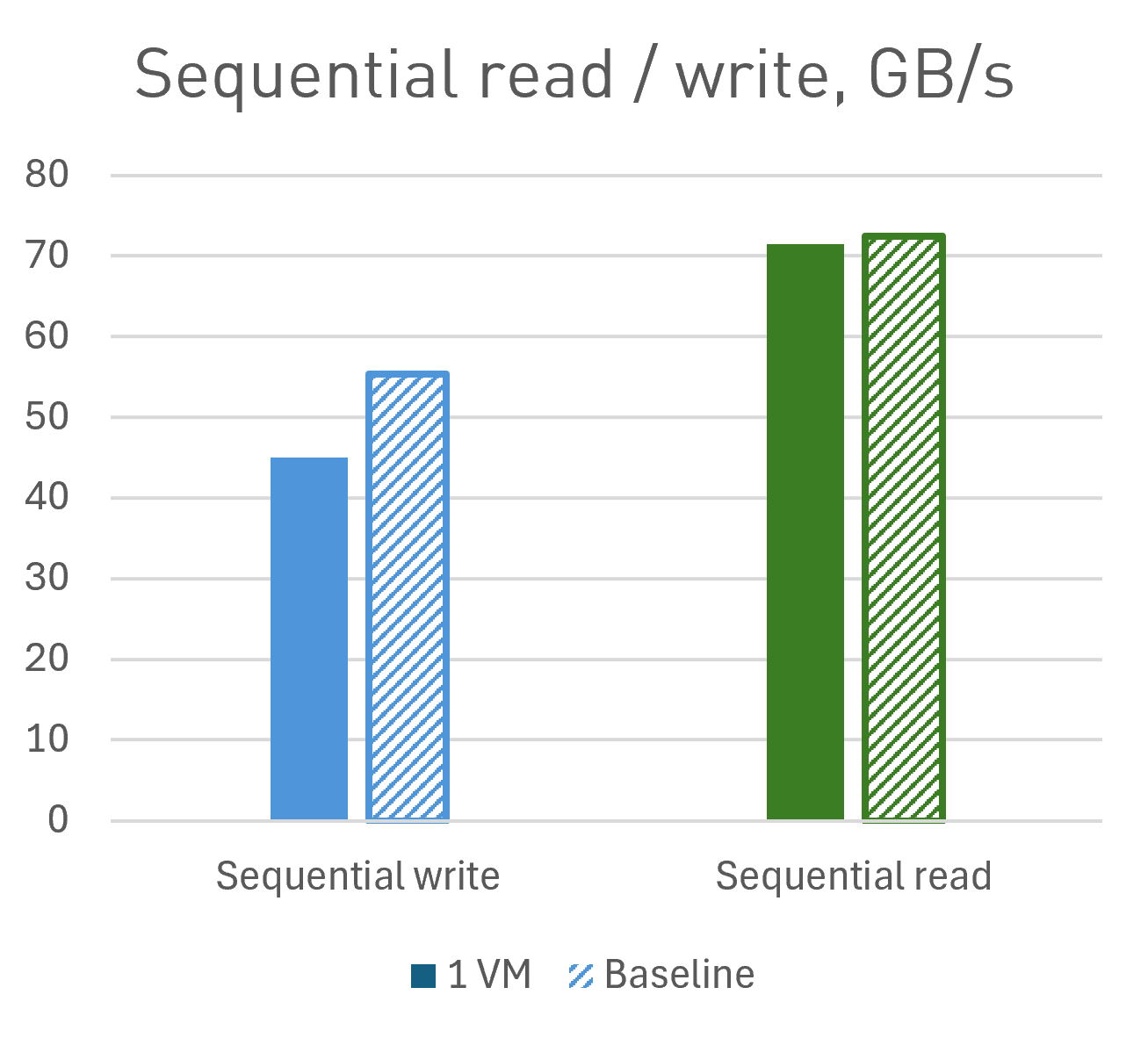
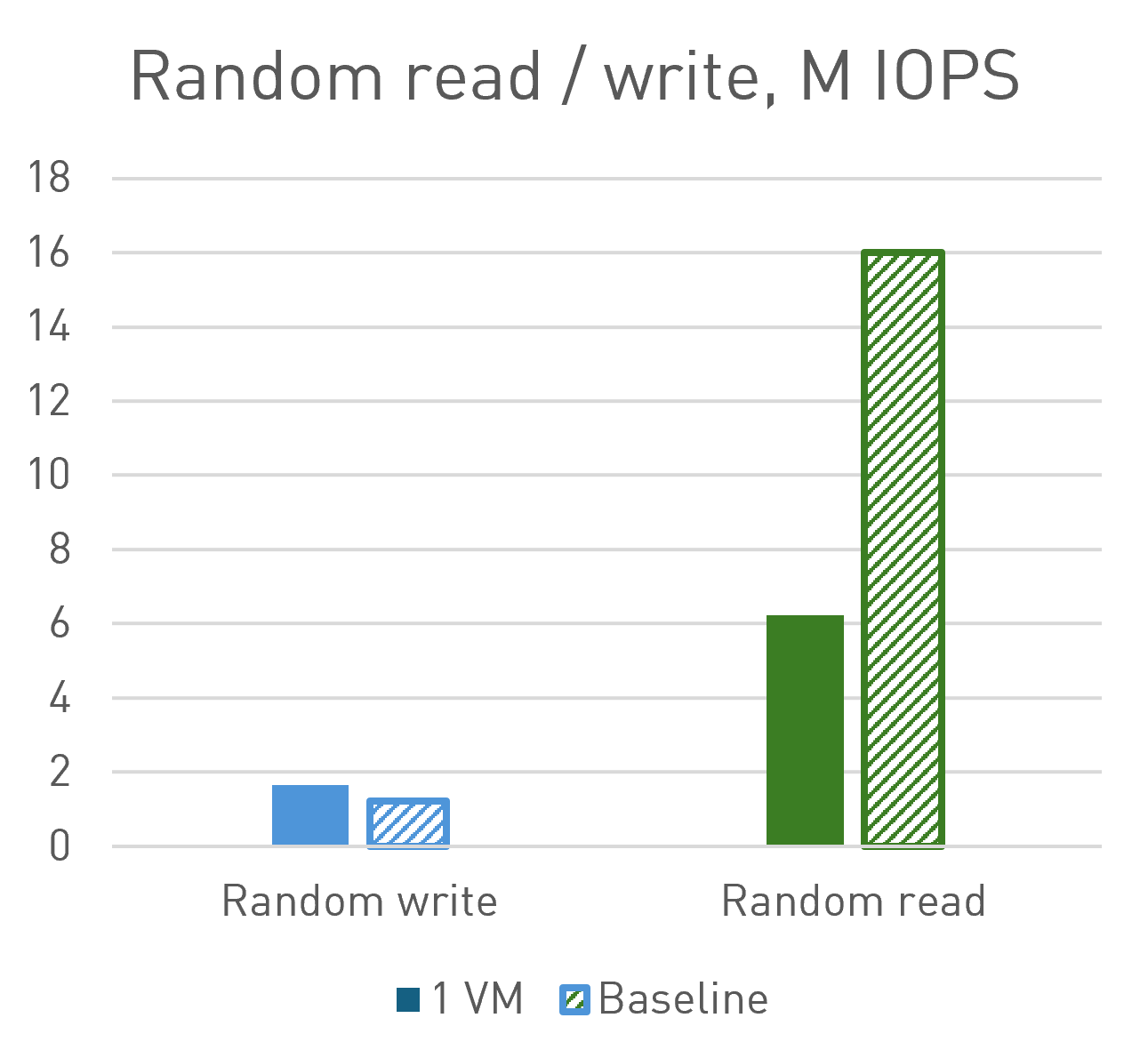
| Performance | Efficiency | |
|---|---|---|
| Sequential write (numjobs=8, queue depth=32) | 45 GB/s | 81% |
| Sequential read (numjobs=8, queue depth=32) | 71,5 GB/s | 99% |
| Random write (numjobs=32, queue depth=32) | 1.7M IOPS | 135%* |
| Random read (numjobs=16, queue depth=128) | 6.2M IOPS | 39% |
Our sequential read and write performance tests have achieved speeds of several tens of GB/s. This level of performance enables the use of virtual machines for demanding tasks that require such high throughput, including HPC and AI applications. Essentially, we can now build solutions for modern, data-intensive workloads with storage that can reach tens of gigabytes per second within a single virtual machine.
(*) In random write operations, we have exceeded the baseline performance. This is due to the user space drivers employed by Opus, which operate in polling mode. These drivers are significantly more efficient than those working in kernel space. This efficiency has allowed us to achieve RAID performance that surpasses the baseline measured in kernel space, resulting in lower latency, higher performance, improved efficiency, and reduced CPU load.
Regarding specific metrics:
- Random Write performance exceeded our expectations.
- For Random Read, while we didn't reach the baseline, this was due to the limitation of 16 cores in the virtual machine. Nevertheless, we achieved an overall performance of 6.2M IOPS, comparable to high-end, expensive storage solutions.
- We attained approximately 400K IOPS per core, whereas kernel-based solutions typically achieve 300K IOPS across all 16 cores. This demonstrates a nearly 20-fold increase in efficiency: 300K IOPS for 16 cores versus 400K IOPS for a single core.
- It's important to note that these results were achieved using a single device. To obtain similar figures using third-party solutions, even with a competing high-performance RAID solution, one would need to deploy 20 block devices within a virtual machine - a setup that would be impractical in real-world scenarios.
Testing multiple VMs
Performance testing was performed from virtual machines using fio-3.36.
Virtual machine configuration:
- Ubuntu 24.04 LTS (6.8.0-35-generic)
- CPU cores: 4
- RAM: 8192 MB
fio sequential read/write config
bs=1M
direct=1
iodepth=32
numjobs=1
group_reporting
rw=read
#rw=write
ioengine=libaio
runtime=600
[vda]
filename=/dev/vda
Results:

| 1 VM, GB/s | 2 VMs, GB/s | 4 VMs, GB/s | 8 VMs, GB/s | |
|---|---|---|---|---|
| Sequential read | 18.9 | 44.4 | 69.9 | 71.2 |
| Sequential write | 10.3 | 18.4 | 27.3 | 50.8 |
Our tests with multiple VMs for sequential write operations demonstrate nearly linear scalability when using small, low-footprint virtual machines. We observed that adding more VMs results in a proportional increase in performance. Under certain configurations, we can achieve backend performance levels, effectively maximizing storage utilization.
fio sequential randread config
bs=4k
direct=1
iodepth=128
numjobs=2
rw=randread
norandommap=1
gtod_reduce=1
group_reporting
randrepeat=0
ioengine=io_uring
hipri=1
fixedbufs=1
registerfiles=1
runtime=60
[vda]
filename=/dev/vda
fio sequential randwrite config
bs=4k
direct=1
iodepth=32
numjobs=4
rw=randwrite
norandommap=1
gtod_reduce=1
group_reporting
randrepeat=0
ioengine=io_uring
hipri=1
fixedbufs=1
registerfiles=1
runtime=60
&nbps;
[vda]
filename=/dev/vda
Results:
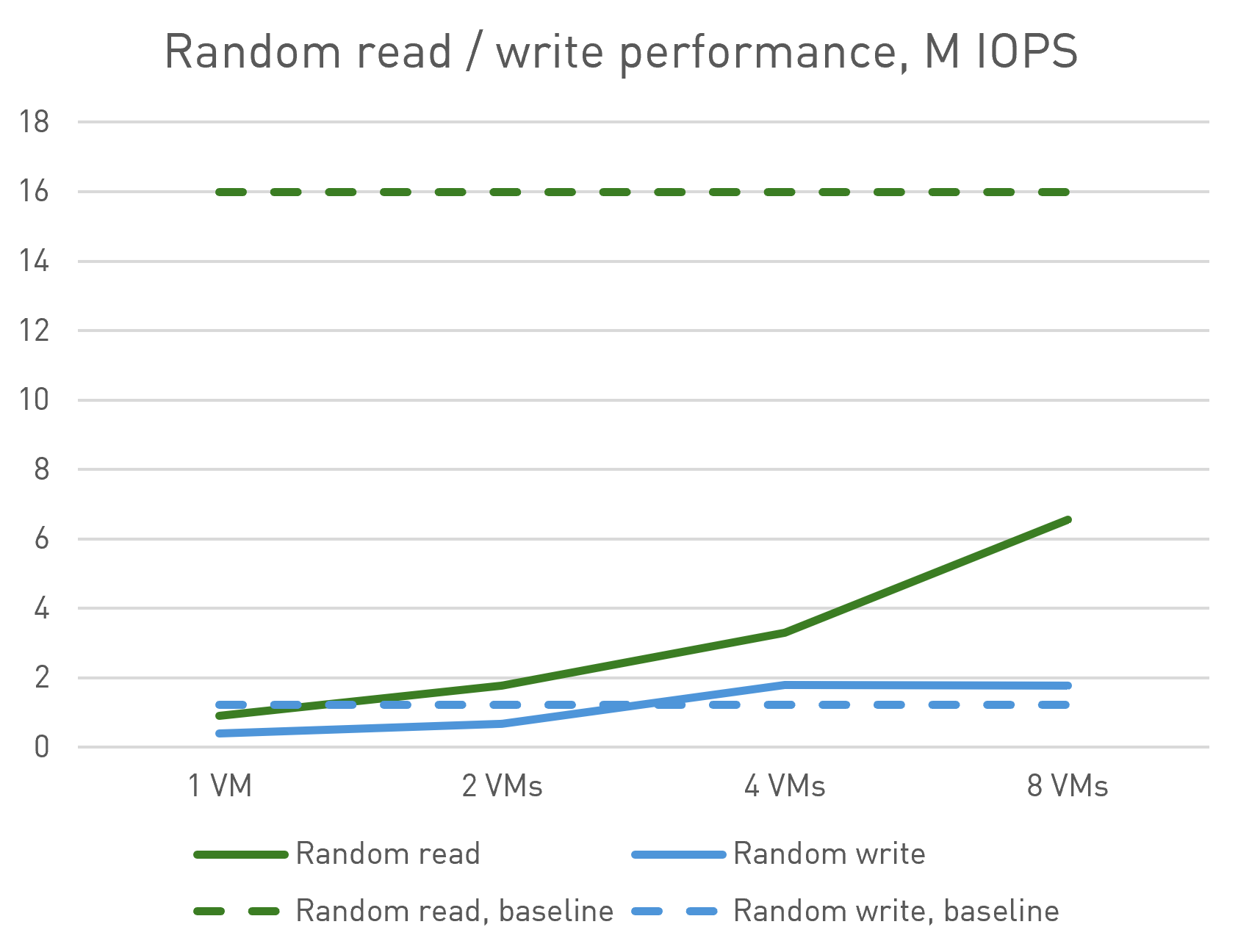
| 1 VM, M IOPS | 2 VMs, M IOPS | 4 VMs, M IOPS | 8 VMs, M IOPS | |
|---|---|---|---|---|
| Random Read | 0.9 | 1.8 | 3.3 | 6.6 |
| Random Write | 0.4 | 0.7 | 1.8 | 1.8 |
For random workloads, we observe similar scalability:
- Random write: performance scales with the addition of small virtual machines, meeting and even exceeding the expected baseline.
- Random read: we achieve performance levels comparable to high-end storage solutions. While we don't reach backend performance, this is primarily due to the limited number of cores in the virtual machines used for testing.
It's important to note that increasing the resources allocated to virtual machines could potentially yield performance in the range of tens of millions of IOPS. For reference, a previous blog post demonstrated achieving approximately 23M IOPS in a similar configuration.
These results indicate that our solution offers excellent scalability and performance across various workload types, with the potential for even higher performance given more powerful virtual machine configurations.
Conclusion
There are significant limitations when using traditional kernel-based solutions for storage management:
- Performance bottleneck. There's a constraint on performance per iothread. This necessitates the use of multiple volumes for high-performance applications, which is both inconvenient and potentially non-functional in some scenarios.
- Degraded mode performance. When using Linux RAID, performance in degraded mode severely impacts real-world application performance, as detailed in one of our previous blog posts.
We have now demonstrated that our solution xiRAID Opus not only works with virtual machines but also integrates seamlessly with Proxmox. xiRAID Opus enables a single virtual machine to achieve performance levels comparable to a large physical server connected to a high-end storage system. This level of performance is typically unattainable with competing solutions, especially within a virtualized environment.
In summary, xiRAID Opus addresses the limitations of kernel-based solutions while offering superior performance and flexibility, particularly in virtualized environments like Proxmox VE.
Appendix
Backend measurements config
Drives Preconditions
rw=write
bs=128K
iodepth=64
direct=1
ioengine=libaio
group_reporting
loops=2
[job1]
filename=/dev/nvme1n1
......
[job10]
filename=/dev/nvme10n1
One Drive Sequential read and write
rw=write (read)
bs=128K
iodepth=32
direct=1
ioengine=libaio
group_reporting
runtime=60
[job1]
filename=/dev/nvme8n1
WRITE: bw=6757MiB/s (7085MB/s), 6757MiB/s-6757MiB/s (7085MB/s-7085MB/s), io=396GiB (425GB), run=60002-60002msec
READ: bw=6920MiB/s (7256MB/s), 6920MiB/s-6920MiB/s (7256MB/s-7256MB/s), io=405GiB (435GB), run=60001-60001msec
One Drive Random Write
direct=1
bs=4k
ioengine=libaio
rw=randwrite
iodepth=128
numjobs=2
random_generator=tausworthe64
runtime=600
[job1]
filename=/dev/nvme10n1
Jobs: 2 (f=2): [w(2)][84.0%][w=1480MiB/s][w=379k IOPS][eta 01m:36s]]]
One Drive Random read
direct=1
bs=4k
ioengine=libaio
rw=randwrite
iodepth=256
numjobs=2
random_generator=tausworthe64
runtime=600
[job1]
filename=/dev/nvme10n1
Jobs: 8 (f=8): [r(8)][100.0%][r=5944MiB/s][r=1522k IOPS][eta 00m:00s]
10 drives sequential tests
direct=1
bs=128k
ioengine=libaio
rw=read
iodepth=32
numjobs=1
norandommap
time_based=1
runtime=600
group_reporting
gtod_reduce=1
[job1]
filename=/dev/nvme1n1
......
[job10]
filename=/dev/nvme10n1
WRITE: bw=64.5GiB/s (69.3GB/s), 64.5GiB/s-64.5GiB/s (69.3GB/s-69.3GB/s), io=278GiB (299GB), run=4313-4313msec
READ: bw=67.6GiB/s (72.5GB/s), 67.6GiB/s-67.6GiB/s (72.5GB/s-72.5GB/s), io=483GiB (519GB), run=7157-7157msec
10 drives random tests (Random Write)
direct=1
bs=4k
ioengine=libaio
rw=randwrite
group_reporting
iodepth=128
numjobs=2
random_generator=tausworthe64
runtime=600
[job1]
filename=/dev/nvme1n1
......
[job10]
filename=/dev/nvme10n1
20 (f=20): [w(20)][8.7%][w=14.0GiB/s][w=3665k IOPS]
10 drives random tests (Random Read)
direct=1
bs=4k
ioengine=libaio
rw=randread
group_reporting
iodepth=256
numjobs=10
random_generator=tausworthe64
runtime=600
[job1]
filename=/dev/nvme1n1
......
[job10]
filename=/dev/nvme10n1
100 (f=100): [r(100)][8.5%][r=61.0GiB/s][r=16.0M IOPS][eta 09m:10s]
VM Configuration example
user@ubuntu2404:~$ hostnamectl
Static hostname: ubuntu2404
Icon name: computer-vm
Chassis: vm
Machine ID: 274cf744d5ef483e928daf8e55174dd5
Boot ID: 10b195927b0a4edc8706ca083e5795d5
Virtualization: KVM
Operating System:
Architecture: x86-64
Hardware Vendor: QEMU
Hardware Model: Standard PC Q35 + ICH9, 2009
Firmware Version: 4.2023.08-4
Firmware Date: Thu 2024-02-15
Firmware Age: 4month 1w 3d
args: -object memory-backend-file,
bios: ovmf
boot: order=scsi0
cores: 4
cpu: host
efidisk0: local-lvm:vm-101-disk-0,efitype=4m,pre-enrolled-keys=1,size=4M
ide2: none,media=cdrom
machine: q35
memory: 8192
meta: creation-qemu=8.1.5,ctime=1719257372
name: Ubuntu01
net0: virtio=BC:24:11:B9:D8:2A,
numa: 0
ostype: l26
scsi0: local-lvm:vm-101-disk-1,size=20G
scsihw: virtio-scsi-single
smbios1: uuid=274cf744-d5ef-483e-928d-af8e55174dd5
sockets: 1
vga: qxl
vmgenid: 59102591-378e-4e54-ace4-f9c9fafb17a1
Useful links
https://kvm-forum.qemu.org/2023/Multiqueue_
https://www.smartx.com/blog/