We use cookies to personalize your site experience.
Privacy policyLustre Acceleration
With an increase in compute performance there comes a need for a proportional increase in storage subsystem capacity and throughput. Thanks to the advancements in NVMe devices we are now able to have storage platforms capable of tens and even hundreds of GB per second throughput.
However, there are a few drawbacks in the classical parallel file system architecture:
- Hardware platforms used for storage nodes are not flexible enough to easily scale in capacity or performance.
- 1+1 High Availability model means that if a node goes down, filesystem performance could potentially be halved.
- Using zfs as back-end filesystem is slow, especially in case of small IO sizes.
These drawbacks can be avoided by using disaggregated storage and a specialized software stack.
Disaggregated storage hardware
Lustre is the leading parallel file system. It is used in most of the top-performing clusters. The file system scales linearly with the addition of new OSS (Object Storage Servers).
External SAN systems were previously used as OSTs(Object Storage Targets), and fault tolerance was achieved using a 1+1 scheme.
This incurred additional costs and the need to double the resources to provide the required level of performance in case of node failures.
Disaggregated Storage for Lustre Insatallations
With the advent of NVMf technology we can now access networked NVMe storage with almost local bus latencies, hundreds of Gb/s throughput and shared flexibility of SAN. Now we don’t need to worry about free bays in the server and adding capacity and performance can be done on the fly.
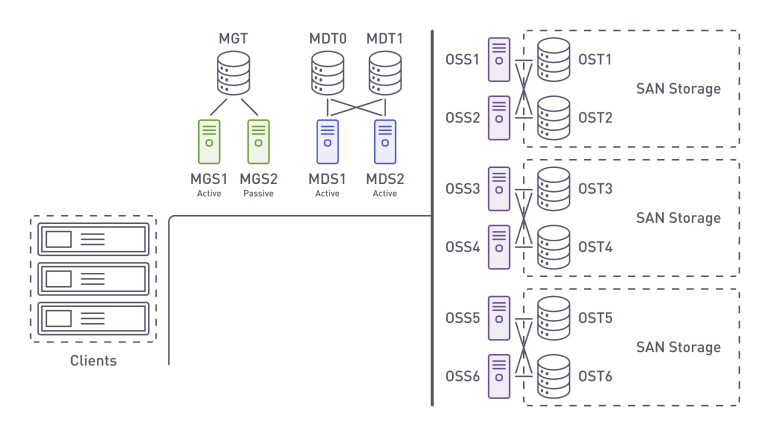
Traditional parallel file system architecture with rigid 1+1 HA model and inflexible storage system attachment
Another important advantage of disaggregated storage is that it allows us to re-attach drives to any server in the cluster, making rigid 1+1 HA model unnecessary.
Any storage target (OST) can be serviced by any storage server (OSS) and in case of server failure, it’sits resources can be spread across several other OSS nodes. This in turn reduces the need for hardware overprovisioning, lowering TCO.
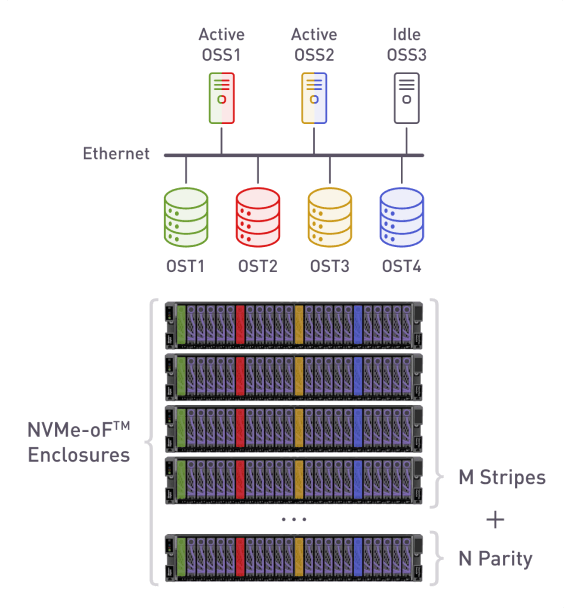
Parallel file system on top of disaggregated storage
With the ability to create one stand by server for the entire storage cluster, we can significantly reduce costs and keep stable performance.
Specialized software stack
In order to enable data protection in a disaggregated environment there needs to be a software RAID solution.
-
Capable of maintaining parity RAID groups (RAID5, RAID6, etc.) of network attached NVMe drives with 10’s of GB/s performance
- Under write-intensive workloads
- In degraded mode
- During rebuilding
- Able to keep data safe in case of network issues.
- Must have migration capabilities to move RAID volumes to another node.
xiRAID is a software RAID solution created for local and disaggregated NVMe storage. It can be used to create and maintain parity-protected high performance OST volumes residing on networked NVMe devices.
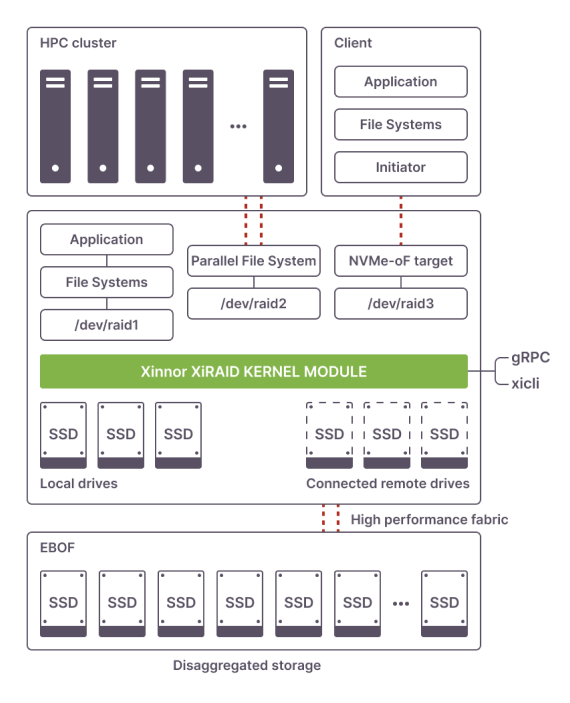
xiRAID placed in the storage stack
The solution
xiRAID is very fast with sequential workloads (it’s discussed in detail in this blog post) and it does granular tracking of all changes to the data, which allows keeping data safe on unstable network with multiple single-strip errors.
Below is a snapshot of our test bench and results from the testing done on LustreFS and Western Digital Ultrastar Data24 NVMf enclosure. You can read about this test in detail in our next blog post.
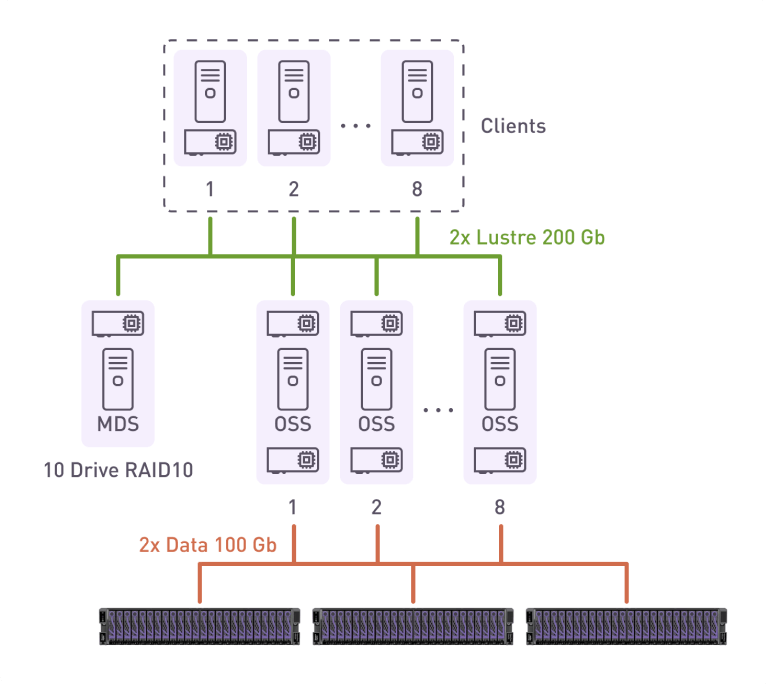
Testing results

xiRAID vs ZFS RAIDZ
An alternative to using xiRAID is to use a ZFS file system with integrated RAIDZ. But using this technology doubles the cost of storage as it limits performance.
The following shows what performance can be achieved on a single OSS using 16 Western Digital SN850 drives (those installed in the OpeFlex Data24).
To achieve 100GBps we need three times fewer servers.
The loss per storage cluster when using ZFS RAIDZ can be tens of GiBs , which will significantly reduce the efficiency of the supercomputer.
