What is a high availability cluster and why it is important
Nowadays, data are the foundation for almost every business; the biggest threat to successful organizations is the loss of their data or the inability to access them. There are different approaches to assure data integrity and availability: the most popular one is creating a highly available cluster, the multi node architecture that distributes the data and system components between several nodes.
An highly available cluster is based on 2 or more servers connected to the same shared drives.
When it comes to NVMe drives, we can use SBB servers (2 nodes in one box with shared NVMe) or independent servers connected to an EBOF (Ethernet-attached Bunch Of Flash). By introducing redundancy, highly available clusters help to reduce the risks of data loss, minimize services downtime and shorten the data unavailability. The logic is that when one node of the cluster fails, the cluster’s logic migrates service components from the failed node to the other node.
Also, since the cluster is naturally a parallel computational system, it enables all the benefits of parallelization: the ability to balance the load by allocating cluster resources across multiple nodes, improved performance by introducing parallelism, and service scalability, as new nodes and services can be added and configured easily.
This solution helps enterprises to reduce the risks of data loss and data unavailability, service interruptions, violation of Service level agreements, extra operational costs and ultimately reduced revenue.
Highly Available cluster from ClusterLabs
Pacemaker, the Open-Source high availability cluster stack for Linux, established its way into the industry since 2004 and is now maintained by ClusterLabs. Pacemaker provides cluster resources orchestration system for Linux Operating System and receives contributions from several major Linux providers like Oracle, SUSE and RedHat.
This stack typically includes the four following components:
- Pacemaker is a software component responsible for the abstract cluster resources management and orchestration. Everything is a resource in this context: application instances, storage volumes, IP addresses etc.
- Each cluster resource type is managed via resource agents. On each node only one instance of the agent is needed to manage multiple instances of the particular resource type.
- Also, a highly available cluster needs the means for node fencing (isolation) to ensure consistency across the cluster during the failover.
- Corosync is a software component that provides a communication bus between cluster nodes. It is not mandatory to use Corosync but it is the default and the most popular communication option for Pacemaker clusters.
Pacemaker is a powerful enabler for clustering full vertical solutions where different components/layers are taken from multiple vendors. Classical example is a stack that contains of a virtual IP + database + filesystem + shared block device. Each component is represented as a cluster resource managed by Pacemaker.
Pacemaker uses the concept of resource and resource agent, so that each application, service or system component in the Pacemaker cluster is represented as a resource. Resources can be allocated into cluster nodes, configured to be dependent on each other, co-located to reflect that some of them must run together or on the contrary to reflect that some of them must be separated. Pacemaker decides on which node each resource should run.
In order to manage resources Pacemaker uses resource agents, apieces of software (most common implementations being bash scripts) which can perform four basic operations: start, stop, monitor and metadata. Agents can optionally implement more actions, but they are not critical for our implementation and we suggest the interested readers to check ClusterLabs documentation.
On each node there is just a single agent needed for each resource type, while there can be multiple different instances of resource. Agents are not running constantly, but only when the cluster manager calls them to perform operations over the resources.
Pacemaker relies on Corosync, the group communication engine and in-memory statistics and configuration database, to synchronize information between the nodes and preform quorum-based decisions. It is possible to use alternatives for this purpose but Corosync is the number one choice, as it is supported by the same team.
What are the major challenges for the clustered storage systems
Coming with benefits, clustering brings its own complications. Two major challenges that naturally exist in every cluster are: the split brain and the amnesia.
The "split brain" problem comes from the fact, that the cluster logic cannot distinct the real node failures from the loss of the connectivity between the nodes. When the connection breaks, individual nodes may mistakenly believe that they are the only active or authoritative member of the cluster, leading to conflicting decisions and potentially causing data inconsistencies or corruption.
For example, if a network partition occurs, nodes on either side of the partition might independently continue to operate and make decisions based on the assumption that they are the only active part of the cluster, potentially leading to divergent data states.
To address the split-brain problem Pacemaker uses two major techniques: quorum and fencing. Quorum allows to make correct decisions about failing over the node resources when the connectivity between portions of the cluster is lost and there are several candidates to run the resource. The quorum rules prescribe that the sub-cluster with the biggest number of nodes wins and takes over the resource processing.
It’s important to understand that quorum can only be used when the number of nodes in the cluster is greater than two, while dual core remains the most popular configuration for storage. First iteration of xiRAID HA works on two nodes configuration only, but we plan supporting multi-node configurations in the near future.
Once the decision is made (via quorum or selected by the engine) about which nodes should run the resource, the other nodes must be isolated and here the second technique, fencing, comes into play. There are multiple different options to isolate failed or unresponsive nodes.
- Power fencing involves shutting down or rebooting unresponsive nodes using power management tools, such as Intelligent Platform Management Interface (IPMI) or Intelligent Power Distribution Units (IPDUs).
- Storage fencing utilizes storage-based mechanisms to prevent failed nodes from accessing shared storage resources, such as SAN (Storage Area Network) or distributed file systems.
- Network fencing involves isolating failed nodes at the network level, typically by blocking network connectivity to the unresponsive nodes.
These mechanisms have their own specific mnemonic name STONITH that stands for “Shoot The Other Node In The Head”. By employing STONITH, Pacemaker ensures that unreliable nodes are effectively isolated from the cluster, preventing them from causing data corruption or other issues, while maintaining the overall integrity and stability of the clustered environment.
The second challenge is amnesia; amnesia can happen when the data stored on one node becomes inaccessible or "forgotten" as a consequence of the node failure. This situation can occur if the cluster lacks the proper mechanisms for consistent data replication and synchronization across its nodes. As a result, if a node fails and is replaced or repaired, there may be data inconsistencies or missing information, leading to potential data loss or corruption. Data stored locally on one node such as RAID configuration are usually vulnerable to amnesia unlike the data stored on the shared drives.
Since there is always a delay between the moment when the cluster understands that the node must be fenced and the moment the fencing happens, there is a chance that the client of the service (in our case – storage service) will receive an acknowledgement for the operation that ends up in the fenced node, but is not replicated on the failover node.
Unlike split-brain, which is a generic problem for cluster and so could be solved by the cluster manager, the amnesia is specific to the particular resource type. The database amnesia is very different from the filesystem or RAID resource amnesia.
And so, in order to address it, we made several changes in xiRAID 4.1.
xiRAID 4.1 changes to support High Availability clusters
The original idea to implement xiRAID in High Availability mode is to expose RAID as a new type of the cluster resource. As xiRAID naturally exposes a particular system resource, the storage block device, it is a perfect candidate for the cluster resource management. Starting xiRAID v4.1.0 we are adding Pacemaker resource agent to the distribution which enables Pacemaker integration. In this case xiRAID takes responsibility to safeguard the data on the underlying drives through RAID technology while the cluster eliminates the single point of failure in the form of xiRAID software instance.
Of course, xiRAID is not the only software RAID manager that can be used, but being the top performing RAID solution, it allows to bring together the performance boost provided by its patented algorithms and the high availability provided by clusterization.
To address amnesia challenge, we added approprate tools to xiRAID 4.1.
In xiRAID 4.1 one single RAID config file is re-designed and now split into multiple config files for each RAID. Additionally, information that is not related to the RAID configuration is taken out of it, while new integrity fields, such as time stamps and checksums are added. But that’s not all, to raise the redundancy even further, full config copies are now stored on each of the drives that are participating in the RAID. This gives total N+1 copies of configuration data for each node for the RAID consisting of N drives.
We also added the additional configuration synchronization mechanism in the form of utility csync2 tool (not to be mixed with Corosync which is used together with Pacemaker) to keep replicated portion in sync between the nodes.
With all these changes xiRAID now receives much more reliable RAID restore logic comprised of:
- read the local RAID config copy
- pick up all the drives that belong to the RAID
- read config copies from each of the disks
- verify checksums, drop copies that can't be verified
- check IDs and time stamps, pick up the latest valid config
- Initiate RAID restore process
This way xiRAID takes care of the consistency of the stored data, while Pacemaker takes care of the xiRAID instances.
The first cluster configuration which we tested is a very common two-nodes configuration. Two nodes put additional challenge as there is no possibility to use quorum (quorum requires an odd number of nodes capable of running the resource, so 3 is a minimum) but in our case fencing proved to work so far. Our next goal is to test multi-nodes cluster, as technically there should be no restriction from xiRAID itself to support it.
In the schematics below, there’s an example of a possible cluster configuration, where xiRAID is used together with the abstract filesystem. Filesystem agent can be either the standard agent provided by ClusterLabs or any specific agent (for example Lustre parallel filesystem provides its own agent).
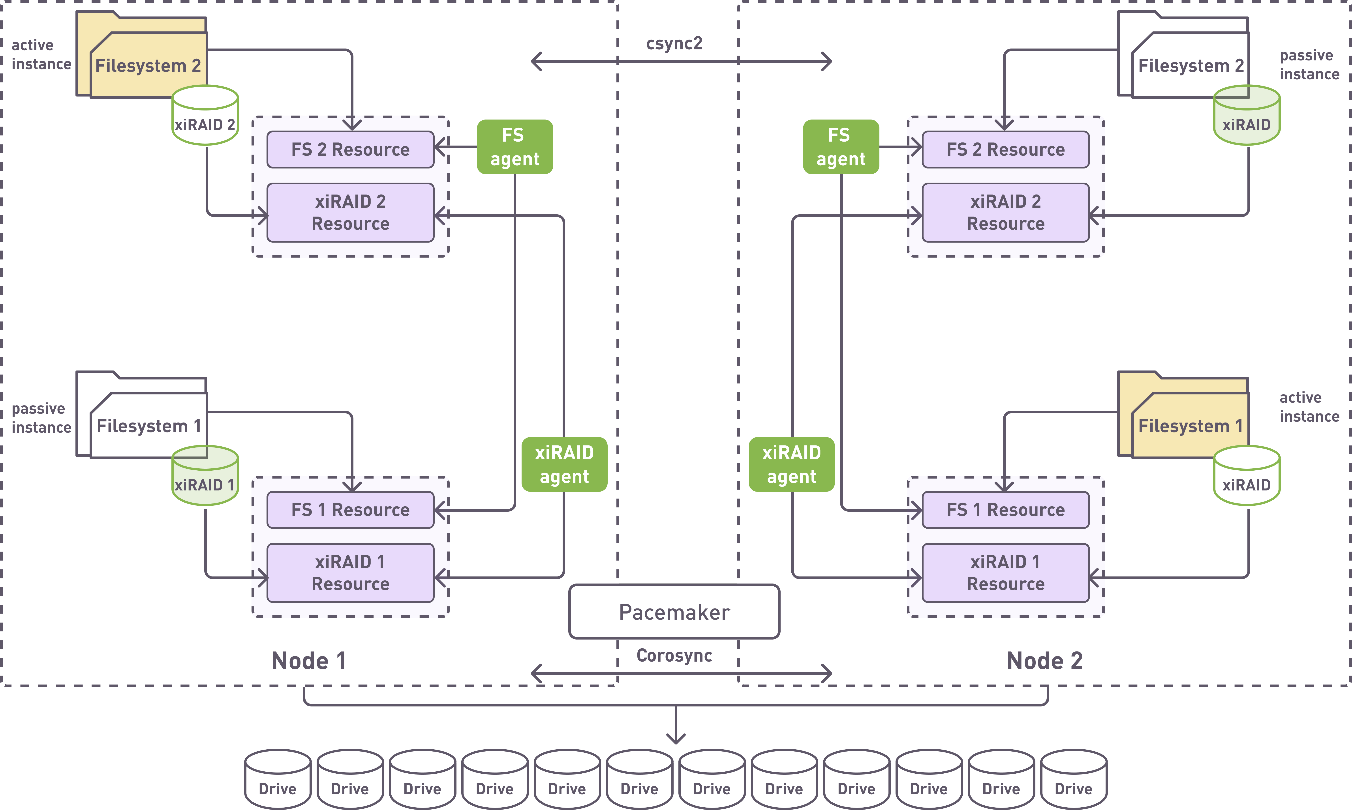
In the second part of this blog post series we will use it in practice and configure xiRAID 4.1.0 within an existing Pacemaker cluster.