Since the introduction of NVMe SSD the question of RAID has been ever-present. Traditional technologies haven’t been able to scale proportionally to the speed increase of new devices, so most multi-drive installation relied on mirroring, sacrificing TCO benefits.
At Xinnor, we applied our wealth of experience in mathematics, software architecture and knowledge of modern CPU, to create a new generation of RAID. A product designed to perform in modern compute and storage environments. A RAID product for NVMe.
Our design goals for the product were simple:
- Today the fastest enterprise storage devices in their raw form can deliver up to 2.5M IOPs and 13 GBps of throughput. We want our RAID groups to deliver at least 90% of these, scaling to dozens of individual devices.
- Our product need to be usable in disaggregated/composable (CDI) infrastructures with network-attached NVMe storage.
- Installation and tuning need to be fast and simple.
- We are a service part of a greater infrastructure, so there should be all the necessary APIs to easily integrate our product with the ecosystem.
- Low CPU and memory footprint. Host resources are precious and they belong to the business application. As a service, we need to be as compact as possible.
The result of this vision is xiRAID – a simple software module of unmatched performance to replace any other hardware, hybrid or software RAID.

xiRAID in relation to other system components
Before we show the solution, let’s take a closer look at the issue. We’ll run a simple test of 24 NVMe devices grouped together with mdraid, which is a staple software RAID for Linux along with its sibling, Intel VROC. Let’s put some random 4k read workload on our bench configuration detailed below:
rw=randrw
bs=4k
rwmixread=100
iodepth=128
direct=1
ioengine=libaio
runtime=600
numjobs=64
gtod_reduce=1
norandommap
randrepeat=0
gtod_reduce=1
buffered=0
size=100%
time_based
refill_buffers
group_reporting
random_generator=tausworthe64
[vol1]
filename=/dev/md0
We observe our test performance hitting a wall just below 2M IOPs. Launching htop we can visualize the issue – some CPU cores are running at 100% load or close to it, some are idle.

What we have now is an unbalanced storage subsystem that is prone to bottlenecks. Add a business application on top of this, and you have a CPU-starved app competing with a CPU-hungry storage service, pushing each other down on the performance chart.
In xiRAID we make it a priority to even out CPU core load and avoid costly locks during stripe refresh. Let’s see it in action.
In our lab, we’re running Oracle Linux 8.4, but the product is available on different Linux distributions and kernels. Our bench configuration is as follows:
System Information:
PROCESSOR: AMD EPYC 7702P 64-Core @ 2.00GHz
Core Count: 64
Extensions: SSE 4.2 + AVX2 + AVX + RDRAND + FSGSBASE
Cache Size: 16 MB
Microcode: 0x830104d
Core Family: Zen 2
Scaling Driver: acpi-cpufreq performance (Boost: Enabled)
GRAPHICS: ASPEED
Screen: 800x600
MOTHERBOARD: Viking Enterprise Solutions RWH1LJ-11.18.00
BIOS Version: RWH1LJ-11.18.00
Chipset: AMD Starship/Matisse
Network: 2 x Mellanox MT2892 + 2 x Intel I350
MEMORY: 8 x 32 GB DDR4-3200MT/s Samsung M393A4K40DB3-CWE
DISK: 2 x Samsung SSD 970 EVO Plus 250GB + 48 x 1920GB SAMSUNG MZWLJ1T9HBJR-00007
File-System: ext4
Mount Options: relatime rw
Disk Scheduler: NONE
Disk Details: raid1 nvme0n1p3[0] nvme1n1p3[1] Block Size: 4096
OPERATING SYSTEM: Oracle Linux 8.4
Kernel: 5.4.17-2102.203.6.el8uek.x86_64 (x86_64)
Compiler: GCC 8.5.0 20210514
Security: itlb_multihit: Not affected
+ l1tf: Not affected
+ mds: Not affected
+ meltdown: Not affected
+ spec_store_bypass: Vulnerable
+ spectre_v1: Vulnerable: __user pointer sanitization and usercopy barriers only; no swapgs barriers
+ spectre_v2: Vulnerable IBPB: disabled STIBP: disabled
+ srbds: Not affected
+ tsx_async_abort: Not affected
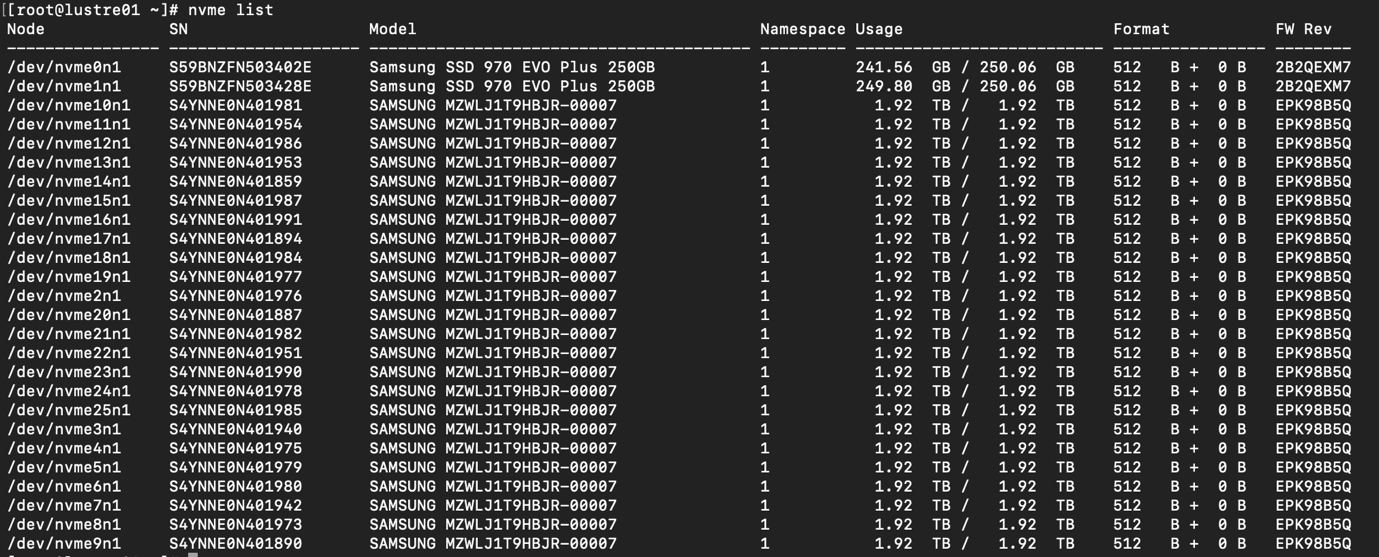
NVMe drives list
Installation steps:
-
Install DKMS dependencies. For Oracle Linux, we need kernel-uek-devel package.
dnf install kernel-uek-devel -
EPEL installation
dnf -y install https://dl.fedoraproject.org/pub/epel/epel-release -latest-8.noarch.rpm -
Adding Xinnor repository
dnf install https://pkg.xinnor.io/repositoryRepository/oracle/8.4/ kver-5.4/xiraid-repo-1.0.0-29. kver.5.4.noarch.rpm -
Installing xiRAID packages
dnf install xiraid-release
At this point the product is ready and you can use it with up to 4 NVMe devices. For larger installations, you’ll need a license key. Please note that we’re providing temporary licenses for POC and benchmarking. -
Array creation
xicli raid create -n xiraid -l 50 -gs 8 -d /dev/nvme[2-25]n1
This will build a RAID 50 volume with 8 drives per group and a total of 24 devices. No extra tuning is applied.
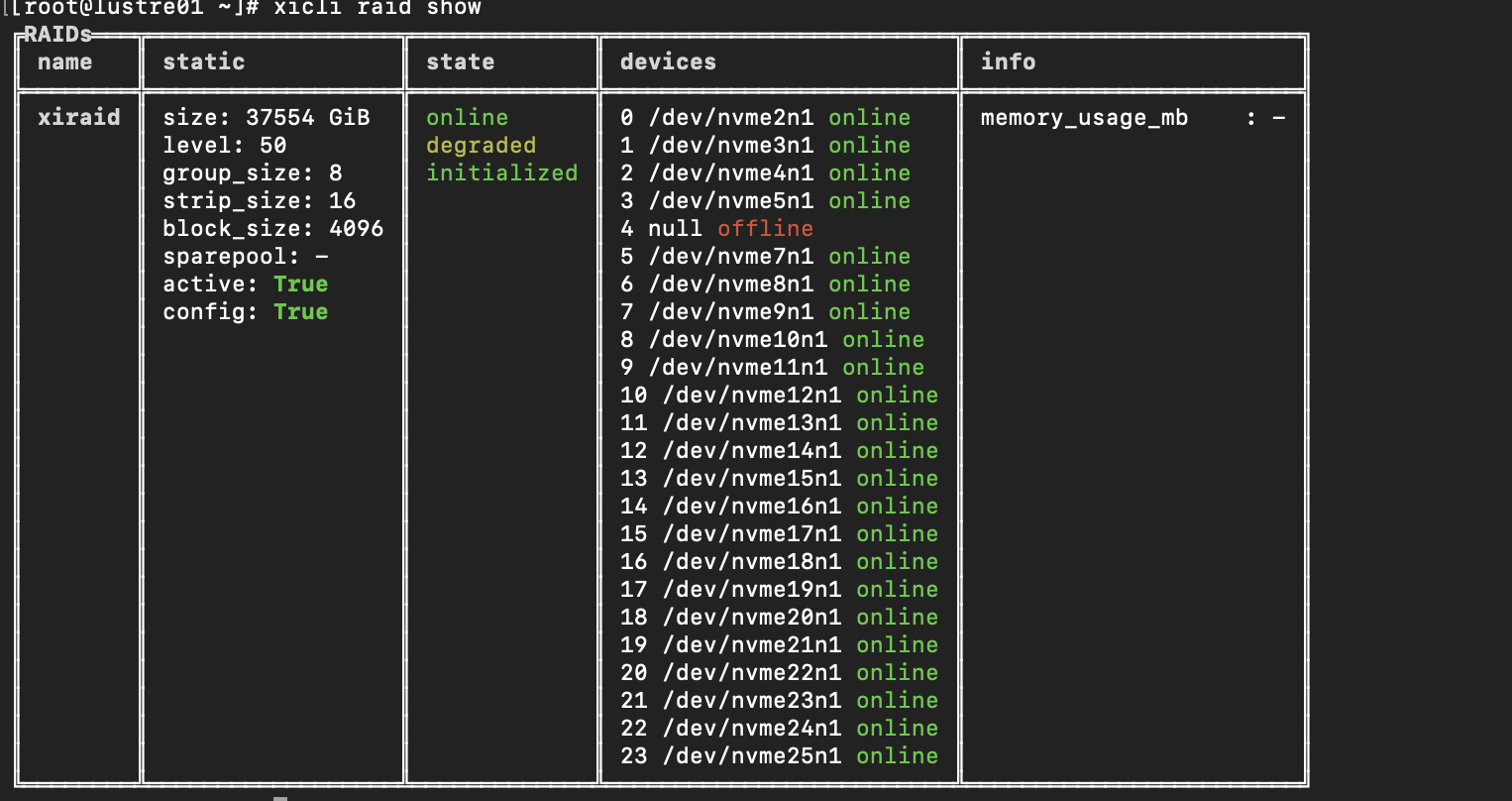
To show the result we use xicli raid show
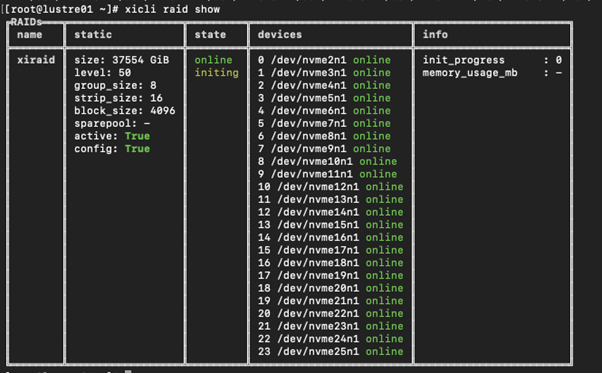
Note: pay attention to the initing state. Full volume initialization is necessary for correct results. Only start tests after it’s done.
While our volume is initializing, let’s have an overview of some of xiRAID features:
-
Multiple supported RAID levels from 0 to 70
- Customizable strip size
- 64 individual storage devices limit
- Customizable group size for RAID 50, 60, 70
- Tunable priority for system tasks: volume initialization and rebuild
- List volumes and their properties
- Grow volumes and change RAID levels
- Create and manage spare pools
Now that our volume is ready, let’s get to the testing.
All our tests are easy to understand and repeat, we are using a reasonably “heavy” system without stretching into the realm of theoretical benchmarks. The results should give you an idea of what our product can do on COTS hardware.
We are sharing all the details so that you could try this in your own environment.
To create a baseline, we’ll first evaluate raw device performance using all 24 SSDs with a series of simple fio tests:
rw=randread / randwrite / randrw rwmixread=50% / randrw rwmixread=70%
bs=4k
iodepth=64
direct=1
ioengine=libaio
runtime=600
numjobs=3
gtod_reduce=1
norandommap
randrepeat=0
gtod_reduce=1
buffered=0
size=100%
time_based
refill_buffers
group_reporting
[job1]
filename=/dev/nvme2n1
[job2]
filename=/dev/nvme3n1
[job3]
filename=/dev/nvme4n1
[job4]
filename=/dev/nvme5n1
[job5]
filename=/dev/nvme6n1
[job6]
filename=/dev/nvme7n1
[job7]
filename=/dev/nvme8n1
[job8]
filename=/dev/nvme9n1
[job9]
filename=/dev/nvme10n1
[job10]
filename=/dev/nvme11n1
[job11]
filename=/dev/nvme12n1
[job12]
filename=/dev/nvme13n1
[job13]
filename=/dev/nvme14n1
[job14]
filename=/dev/nvme15n1
[job15]
filename=/dev/nvme16n1
[job16]
filename=/dev/nvme17n1
[job17]
filename=/dev/nvme18n1
[job18]
filename=/dev/nvme19n1
[job19]
filename=/dev/nvme20n1
[job20]
filename=/dev/nvme21n1
[job21]
filename=/dev/nvme22n1
[job22]
filename=/dev/nvme23n1
Baseline results for 4k block size:
17.3M IOps random read
2.3M IOps random write
4M IOps 50/50 mixed
5.7M IOps 70/30 mixed
An important note for write testing: due to the nature of NAND flash, fresh drive write performance differs greatly from sustained performance, once NAND garbage collection is running on the drives. In order to get the results that are repeatable and closely match real-world production environments, a pre-conditioning of the drives is necessary as described in SNIA methodology: https://www.snia.org/tech_activities/
We are following this specification for all our benchmarks.
Proper pre-conditioning techniques are out of the scope of this publication, but in general a drive sanitize, followed by overwriting the entire drive capacity twice, immediately followed by the test workload is good enough for most simple benchmarks.
Now that we have our baseline, let’s test xiRAID:
rw=randrw
bs=4k
rwmixread=100 / 0 / 70
iodepth=128
direct=1
ioengine=libaio
runtime=600
numjobs=64
gtod_reduce=1
norandommap
randrepeat=0
gtod_reduce=1
buffered=0
size=100%
time_based
refill_buffers
group_reporting
random_generator=tausworthe64
[vol1]
filename=/dev/xnr_xiraid
xiRAID RAID50 4k results:
16.8M IOps random reads
1.1M IOps random writes
3.7M IOps mixed rw
Comparing to baseline xiRAID performs at
97% for random reads – this is industry fastest RAID performance
48% for random writes – this is almost at the theoretical maximum due to read-modify-write RAID penalty
One extra step in our benchmark is always a test of system performance in degraded mode, with one device failed.
The simplest way to simulate a drive failure with xiRAID CLI:
Re-run the tests with the following results:
14.3M IOps random reads
1.1M IOps random writes
3.1M IOps mixed rw
We see a 15% maximum drop of performance in degraded state with xiRAID, compared to 50-60% in other solutions.
TL;DR summary of xiRAID benchmark: we were able to get an industry-leading result of a software RAID50 volume operating at 97% of baseline during random read tests, dropping 15% during a simulated drive failure.
Summary table (for your convenience, we have rounded the results to hundreds of kIOPS):
| Random read 4k, kIOPS | % | |
|---|---|---|
| Baseline raw performance | 17300 | 100.00% |
| xiRAID | 16800 | 97.11% |
| xiRAID degraded | 14300 | 82.66% |
| MDRAID | 1900 | 10.98% |
| MDRAID Degraided | 200 | 1.17% |
| ZFS | 500 | 2.89% |
| ZFS Degraded | 500 | 2.89% |
| Random write 4k, kIOPS | % | |
|---|---|---|
| Baseline | 2300 | 100.00% |
| xiRAID | 1100 | 47.83% |
| MDRAID | 200 | 8.70% |
| ZFS | 60 | 2.6% |
We at Xinnor encourage you to run similar tests on your own infrastructure. Feel free to reach out to us at request@xinnor.io for detailed installation instructions and trial licenses.