In this post we will tell you why we like the idea of disaggregated storage and why we try to create solutions using this approach.
Let's go back for a few years:
Once upon a time, NAND flash could not demonstrate all its capabilities because of outdated interfaces, made primarily for spinning disk drives.
Some companies created their own command set for SSDs to get rid of this bottleneck with various results.
But everything changed with the advent of the NVM Express specification.
SSDs have become incredibly powerful and can reach above 7GB/s speeds and over 1 million IOps per drive. And with the adoption of PCIe Gen 5 (which will happen very soon) the speed will double.
But consumers of NVMe systems face new challenges:
- Existing software and RAID controllers cannot handle these performance levels. Because of this, the capabilities of today's drives are often not utilized.
- Network storage systems on new types of drives will most often be priced very high or have lackluster performance.
EBOFs and “dark flash”
Fortunately, with NVMeoF we can export drives over a network with near-local performance and this changes the whole game. Systems have emerged that allow on-demand delivery of the right device to the right server.

Western Digital OpenFlex Data24 EBOF
This approach helps us solve several problems at once:
- We can get the right volume and performance on the server, regardless of the number of free slots (but the performance will still be limited by the network capacity).
- We can use shared storage where we need it without investing heavily in a high-performance SAN (but there are nuances to consider with fault tolerance).
- We have the flexibility to get rid of the "dark flash" - underutilized SSD capacity siloed inside servers.
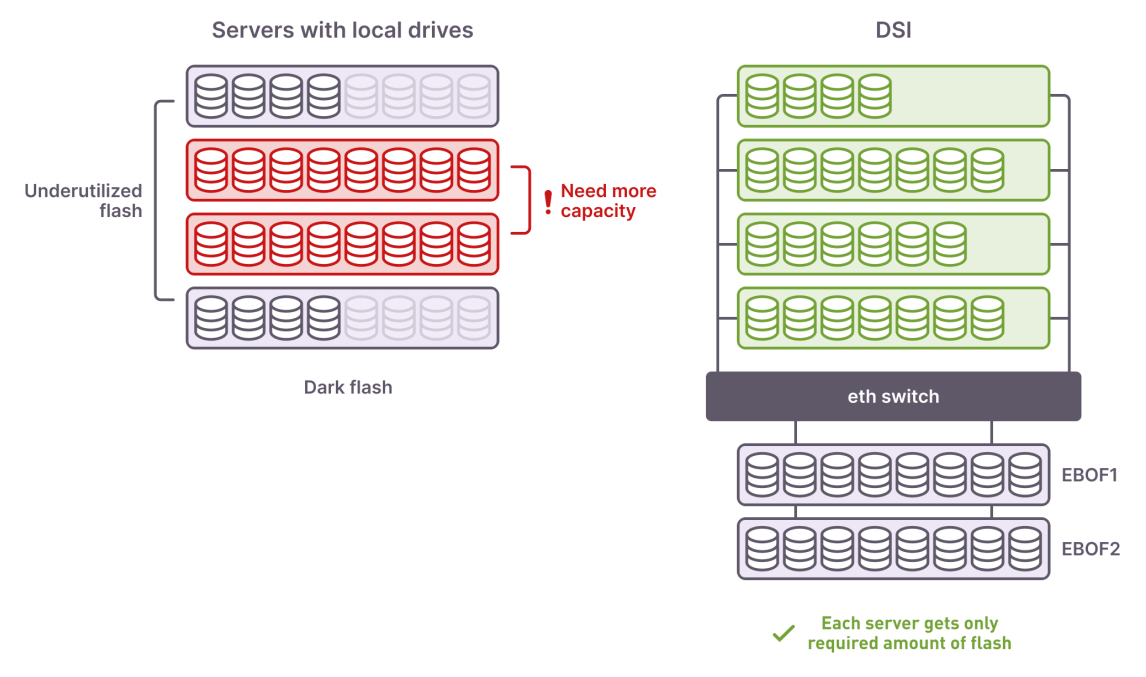
Local silos of flash in servers vs NVMeoF disaggregated storage
Networked NVMe in practice
Before moving on to theory and product reviews, let’s have a look at a couple of practical examples.
The first example is from our server room, because we are not used to recommending solutions that we haven’t tried ourselves.
We use both real and virtual servers for product development and testing purposes. In order to provide each team with high-performance servers packed with NVMe drives, we would have had to spend a substantial sum of money. That said, at any given time, no one is using all of the server's capabilities, so when physical servers packed with NVMe are used, most of the SSD capacity is “dark flash” siloed and not used. Disaggregation helps us save significantly on capital costs and choose server platforms without regard to the number of NVMe slots.
Another example scenario that we saw at one of our partners. We needed many NVMe devices to run a PoC and high-performance benchmarking. Without EBOFs we would need dozens of servers with NVMe backplanes, but with disaggregated storage we could run the tests with much simpler server platforms just by adding 100GE NICs.
Separately, we can mention solutions for parallel file systems in supercomputer infrastructure, but we will discuss them in much more detail in our blog posts.
NVMeoF infrastructure
Back to theory. There are two types of EBOFs for disaggregated infrastructures:
- Conventional servers with high-performance Ethernet/IB/FC cards.
- Systems with purpose-built controllers and DPUs.
The main advantage of the former is high flexibility: one can combine and change host interfaces, update fabric target drivers as soon as new ones appear, or swap 100Gb SmarNICs for 200G and higher.
This is where the positives end.
The cost of such solutions is higher, they often do not have fault tolerance and the issue must be resolved on a higher level, which we will talk about.
The latter were originally developed by companies with experience in creating storage: they have the right level of fault tolerance, are well-balanced and stable.
But there are also disadvantages:
If there is a problem with support for one of the components, you have nothing to replace it with, some solutions, for example, were built on Broadcom Stingray, the production of which is stopped. In most cases these systems can’t be upgraded to the next generation of the network.

Western Digital OpenFlex Data24 has 2 independent IO modules and 6 total 100GbE ports

Western Digital RapidFlex – NVMeoF bridge controller powering several leading brands of EBOF systems
In general, both the first and the second solutions can do their job perfectly. We will gradually describe all such products in a series of posts.
A typical approach to using disaggregated storage infrastructures is as follows:
- Select the right hardware: here you will need to choose EBOF, network switches and NICs.
- Configure the network for your NVMeoF protocol of choice.
- Set up the initiator with proper NVMeoF drivers on the host OS and connect the drives to the OS.
With large storage infrastructures, you may need a CDI orchestrator to automate tasks.
At this point disaggregated storage might start to look too complicated and expensive, compared to the simplicity of just adding some NVMe drives into a server. But in the long run, the efficiencies of shared storage are always worth it.
One can manage EBOF resources in several ways:
- Via UI: GUI or CLI.
- Using APIs.
Western Digital is developing the Open Composable API to enable unified management of different resources.
Data protection and fault tolerance
One of the most important issues is the ability to provide fault tolerance on top of EBOF and there are the following ways:
- Replication of data at the application level
-
Using SDS or distributed file system with replication or erasure coding
- Unfortunately, replication has a major disadvantage - it doubles the cost of storage
-
“Ye goode olde RAIDe” - traditional RAID controllers with NVMe features
- HW RAID can’t work with networked NVMe yet
- Performance is bottlenecked at both PCIe bus and onboard SoC levels
- Networked storage could potentially be much more capricious than direct-attach SAS, so unless you want to restart your volumes after every network glitch, you need to have much more network-aware controllers
At Xinnor we have tried to take all features of NVMe, including network-connected devices, into account when developing xiRAID. Thanks to numerous tests, including those conducted by our partners, we are ready to handle network configuration errors and multipath-connected devices.
Keeping networked RAID volumes safe
You can read about the performance in previous posts, and in this one we will talk about the modified reconstruction mechanism.
In the classic approach, each I/O error causes a drive to be marked as failed and just two of these in RAID 5 is enough to cause the array to "crash". When using NVMe drives we have hundreds of thousands of IOs and deep queues, which with switching problems can lead to many failures at once. xiRAID can handle multiple failures if they occur in different stripes. For each drive, we keep a bitmap of failures and data updates, which allows us to reconstruct only the affected parts of the drive, in case of transient errors.
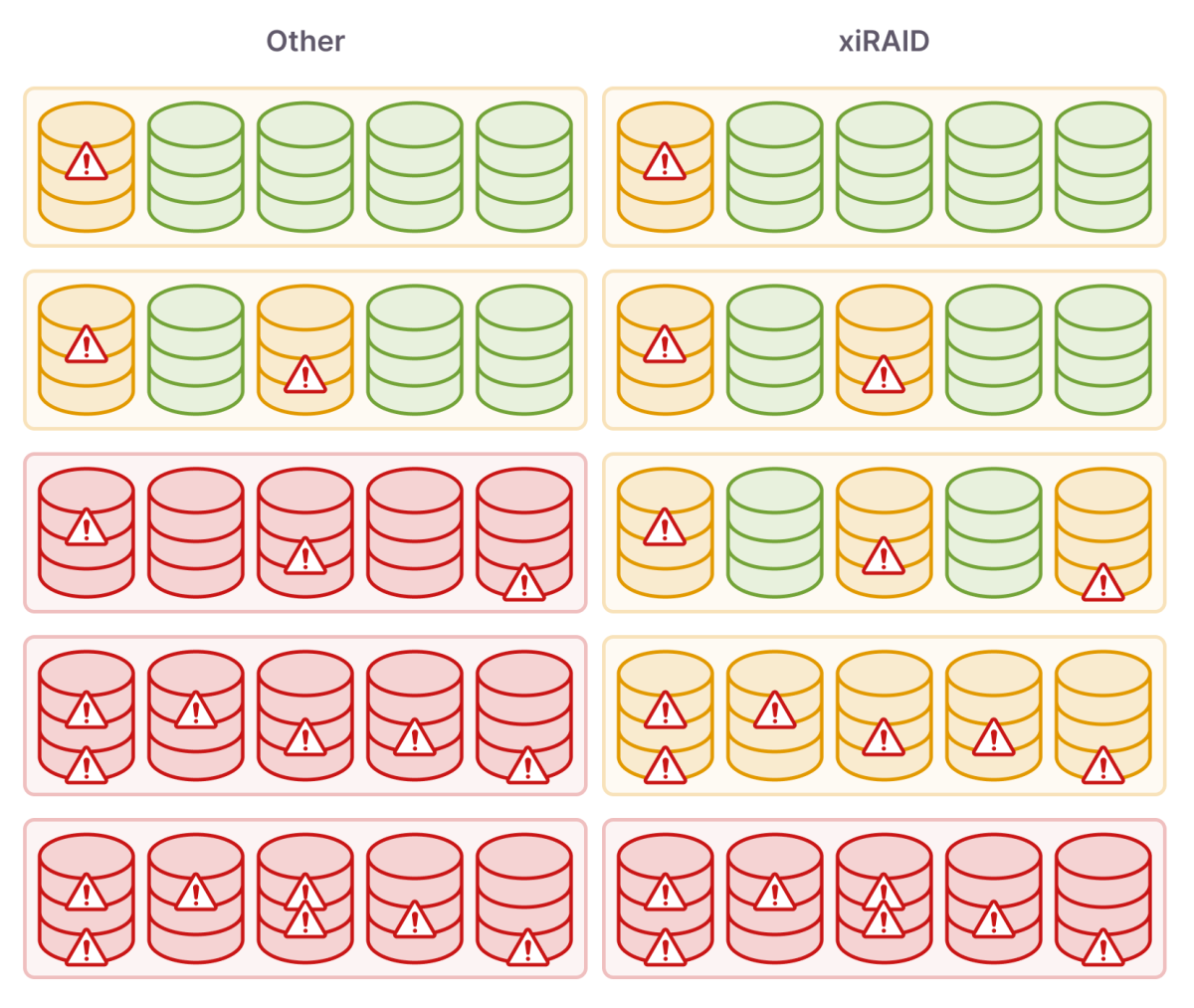
NVMf has allowed us to significantly increase the efficiency of modern storage infrastructures but requires special attention to the software to be used.