Introduction
Parallel file systems are the heart of the most demanding HPC workloads. As the need for computing power grows, so does the complexity of storage systems. I/O becomes more intensive, complex, and interdependent.The performance of parallel file systems must meet the requirements of computing clusters, and there are technologies that help with this.
On the hardware side, NVMe SSDs offer the highest throughput and lowest latency, and NVMeoF protocols allow shared networked access much faster than traditional SCSI-based storage attachment technologies (iSER, FC, SAS, etc.)
Xinnor xiRAID is a software RAID engine that enables fast parity data protection for NVMe.This solves one of the key issues that make using NVMe less attractive. Traditional hardware RAID solutions haven’t scaled up well to NVMe speeds and software options are even slower. As a result, many installations are using NVMe as scratch space or deploying mirrored configurations that are expensive.
In this blog post we’ll show how xiRAID can help deploy parallel file systems on NVMe storage in a way that’s optimal for data integrity, performance and TCO. We’ll use a simple Lustre parallel file system structure with a single MDS/MGS instance and multiple OSS instances.
Traditional Lustre HA Node approach
A traditional approach for a Lustre file system high availability architecture is shown below (Fig.1). This architecture is based on classical JBODs and SCSI drives connected to a pair of initiators.
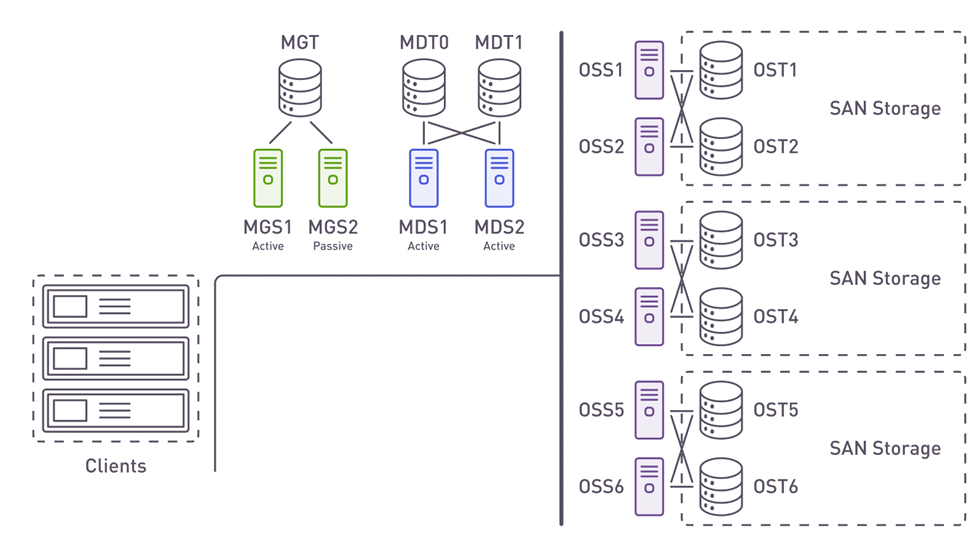
Fig.1 - Traditional SCSI JBOD-based Lustre storage model
There are standard management and metadata services (above) as well as object storage servers (at the right). All servers are setup as failover pairs and each pair has a resilient connection to SAN volume(s) or JBOD(s). In case of a storage server (OSS) failure, its storage target (OST) is failed over to the remaining OSS in the pair to keep data available.
This approach has several drawbacks:
-
A server failure and subsequent failover may reduce performance because of a double workload on the remaining server in the failover pair.
The possible bottlenecks are:- CPU performance
- Server to JBOD(s) or SAN volume(s) connection throughput
- Server Lustre network interface (LNET) throughput
- A single server performance reduction may spread cluster-wide, because a parallel file system moves as fast as its slowest part.
- While such performance reduction could be planned for during cluster design, it would necessarily lead to over-provisioning of server and network resources and increase costs significantly.
- A JBOD failure could be catastrophic for the cluster. Even though most storage systems have redundant active parts (PSUs, IO modules, fans, etc.), the chassis itself and the backplane are still single points of failure.
Lustre NVMe-oF storage architecture
The proposed NVMe-oF approach is based on using EBOFs. An EBOF is essentially very similar to a JBOD. It’s “just a bunch of drives” but uses flash (NVMe) storage instead of HDDs and connects by high speed Ethernet with NVMe-OF support instead of SAS.
Western Digital’s 2U24 NVMe-oF JBOF enables standard NVMe PCIe SSDs to be shared in an external enclosure with the following parameters:
- 2U enclosure with dual IO Modules for HA
- Similar design to existing SAS SSD enclosures
- 24 standard dual-port NVMe PCIe SSDs
- No data services (i.e. no RAID). Just pass through
Networking parameters:
- 2-6 Ethernet ports
- RoCE v2 or TCP
- RJ45 management port
- REST based management

Fig.2 - NVMe-oF JBOF (EBOF)
A simplistic view of a Lustre architecture with NVMe-oF storage targets as we’ll be using for performance tests:
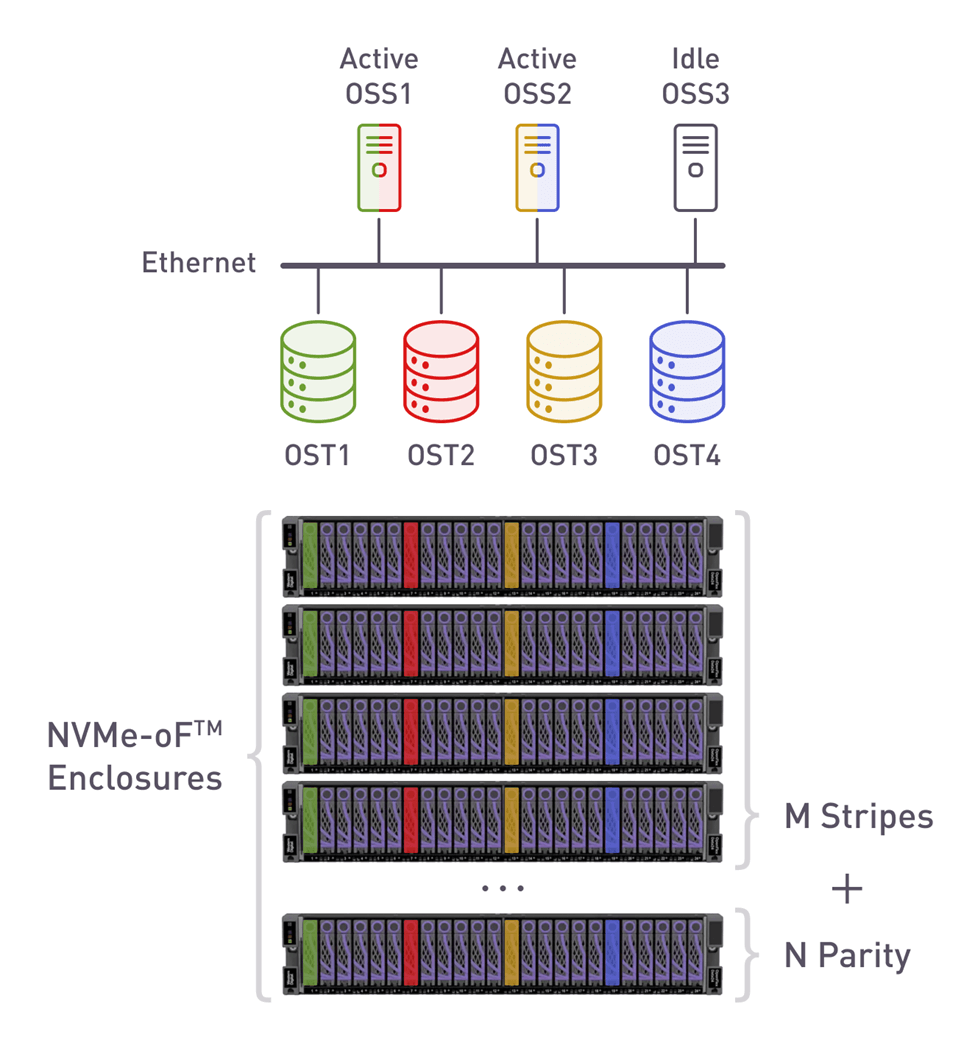
Fig.3 - Lustre with NVMe-oF
Architecture highlights:
- Use 1 or more devices from each EBOF to create a RAID stripe
- Stripe can be any RAID layout 4+1, 7+1, 8+1, 8+2, N+M
- Any OSS can serve any OST – no fixed pairing
- Idle OSS can take over in case of any OSS failure
- Active OSS can host as many OST volumes as they’re capable of – no 50% reserve needed
- xiRAID high performance enables improved OSS-to-OST ratio
Benefits:
- Any SSD/Server/EBOF/Network link may fail without performance degradation
- RAID not limited to a single HA node
- Reduced server overprovisioning (=reduced server costs)
- Improved overall performance because of xiRAID
Solution PoC
We did a limited testing of the concept with some simplifications, described at the end of the section.
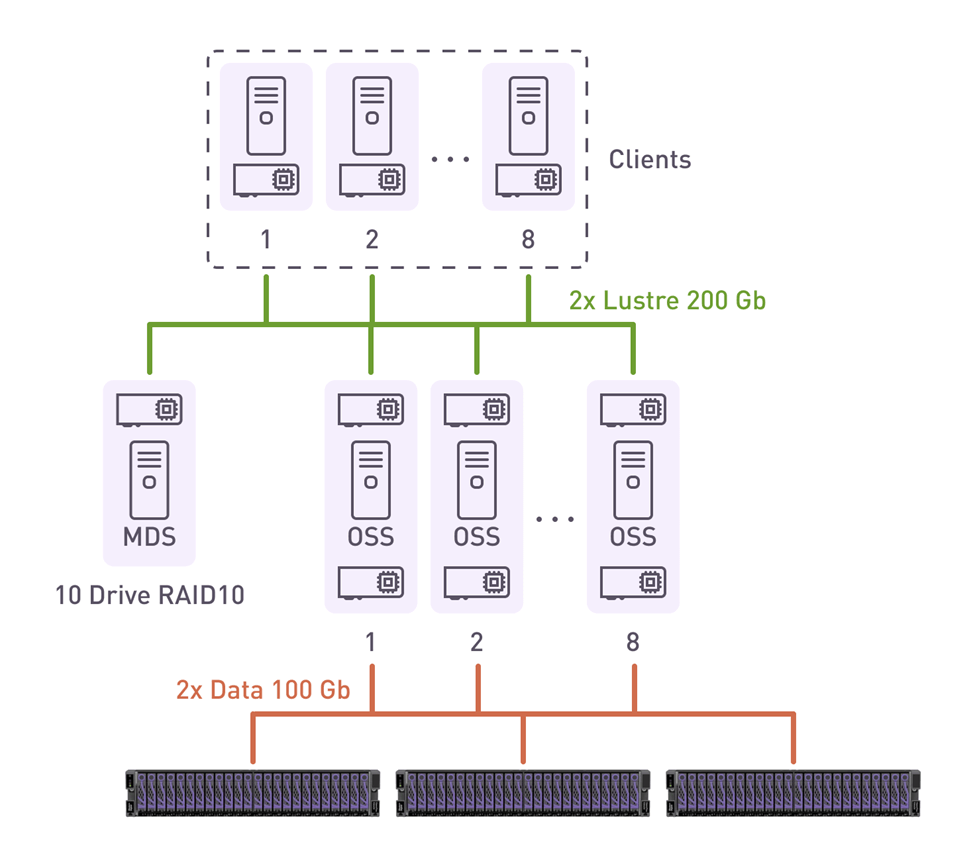
Fig.4 - PoC diagram
Hardware configuration
We used OSS and MDS servers based on 3rd generation Intel Xeon Scalable processors.
XiRAID is CPU-accelerated, meaning that it uses SSE and AVX instruction sets to provide the highest parity calculation and data recovery rates.
With support for up to 64 PCIe 4.0 lanes per socket, we were able to use 200 Gbit/s network adapters.
12 cores and 24 threads give us the ability to efficiently process many write streams simultaneously without locking and efficiently write to high-performance NVMe drives.
MDS server – 1 pc.
Hardware:
- Platform: Dell R650
- Processor: 2 x Intel 5317 150TDP 12-Core 3.0GHz
- Memory: 128GB
- Fabric: 1 x ConnectX-6 200Gb Dual Port Ethernet HCA
- Storage (local): 10 x 3.2TB WDC SN640 NVMe SSD
Software:
- Operating system: RHEL 8.3
- Kernel: kernel-4.18.0-240.1.1.el8_lustre.x86_64
- Network stack: In-Box Mellanox 5.0.0
- Lustre: 2.14.0-1
OSS server – 8 pcs.
Hardware:
- Platform: Dell R650
- Processor: 2 x Intel 5317 150TDP 12-Core 3.0GHz
- Memory: 128GB
- Fabric: 2 x ConnectX-6 200Gb Dual Port Ethernet HCA
- Storage (remote): remote NVMeOF
Software:
- Operating system: RHEL 8.3
- Kernel: kernel-4.18.0-240.1.1.el8_lustre.x86_64
- Network stack: In-Box Mellanox 5.0.0
- Lustre: 2.14.0-1
- RAID Software: xiRAID 3.3.0-289
- Multipath setup option: Native NVMe Multipathing
- Lustre network: LNET RoCEv2 with o2ib
- NVMe-OF storage network: RoCEv2 with Priority Flow Control
Clients – 8 pcs.
Hardware:
- Platform: Dell R750
- Processor: 2 x Intel 6354 205TDP 18-Core 3.0GHz
- Memory: 512GB
- Fabric: 1 x ConnectX-6 200Gb Dual Port Ethernet HCA
Software:
- Operating system: RHEL 8.3
- Kernel: kernel-4.18.0-22.1.el8_3.x86_64
- Network stack: In-Box Mellanox 5.0.0
- Lustre: 2.14.0-1
- Lustre network RoCEv2 with o2ib
Networking and storage
SN3800 – 64-Port 100Gb Switch:
- Storage subnets 1 & 2
- Lustre network 1
SN2700 - 64-Port 100Gb Switch
- Lustre subnet 2
Western Digital OpenFlex Data24 NVMe-OF with 24
Ultrastar DC SN840 3.2TB – 3 pcs.
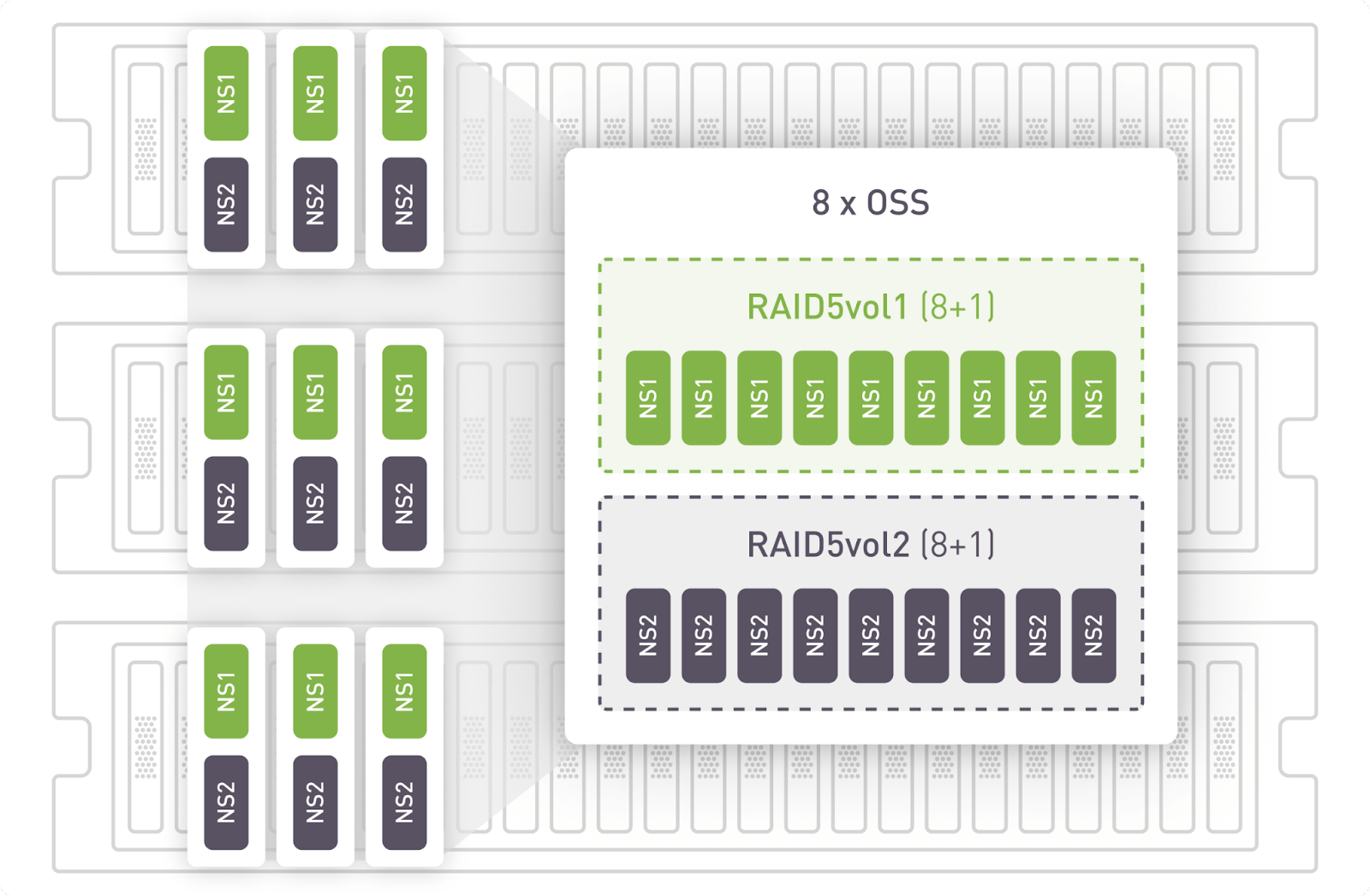
Storage configuration
Each Ultrastar DC SN840 3.2TB NVMe at the EBOFs is split into two namespaces 1.6TB each to get the needed number of devices for the configuration. Combined, three Data24 chassis present 144 virtual NVMe devices to the OSS servers over NVMeoF/RoCEv2.
Each OSS server used 9 namespaces (3 from each EBOF) to create RAID 5 volumes, 2 volumes per OSS. A stripe size of 16K was used.
Tests description and results
The system was benchmarked with FIO and IOR.
Flexible I/O Tester (fio) – a standard tool for testing and benchmarking raw device and file over a filesystem performance. Fio was used to benchmark raw NVMe performance for all 18 NVMes running at each OSS (RAW column in results table), performance of both xiRAIDs running at each OSS (xiRAID column in results table) and total Lustre file system performance running at each Lustre client (last column). A standard Lustre benchmark IOR was used to test the filesystem.
After benchmarking we used RAW performance as baseline and compared xiRAID and Lustre with RAW.
The benchmark settings are as follows:
FIO benchmark
Test configurations:
RAW – each OSS tests 18 namespaces
xiRAID – each OSS tests 2 RAID5 of 9 namespaces
Lustre - 48 x 256GB test files per client, each file in own subdirectory
Test patterns:
- 2 x 128k sequential fills
- 1 x 128k sequential writes (20 minutes)
- 1 x 128k sequential reads (20 minutes)
Run test 3 times and average the results
Fio configuration:
- IO Engine: libaio
- 10 jobs per file
- 128k sequential reads and writes
- Queue depth of 16
- DirectIO enabled
File structure (for Lustre test (3)):
- Lustre stripe count = “-1” (stripe files over all available OSTs)
- Each client had its own directory
- Each client had 48 x 256GB test files, in own subdirectory
IOR benchmark:
File structure:
- Lustre stripe count = “-1” (stripe files over all available OSTs)
- Each client had its own directory
- Each client had 36 x 512GB test files, each file in own subdirectory
IOR configuration:
- MPI: OpenMPI
- IO Engine: AIO
- 1MB sequential reads and writes
- 288 Processes
- DirectIO enabled
- Collective IO
- Reordered Tasks
- ‘fsync’ on write close
Testing methodology: run 4 iterations and average the results.
Results and conclusion
| Raw (FIO) | xiRAID (FIO) | Lustre FS over xiRAID (IOR) | |
|---|---|---|---|
| Sequential write (GB/s) | 119.84 | 112.14 | 96.51 |
| Sequential read | 182.13 | 184.16 | 177.36 |
| Sequential write (% of RAW) | - | 94% | 81% |
| Sequential read (% of RAW) | - | 101% | 97% |
Conclusion
- The performance at the Lustre clients is very close to raw drive performance. This proves Lustre and xiRAID ability to fully utilize NVMes with the proposed deployment architecture.
- Raw and xiRAID results are very close, and in case of reads xiRAID is faster than raw. This is explained by the fact that on the drive level 128K requests are slower than 8 x 16K requests, so xiRAID spreading 128K operations as 8x 16K requests is faster than 9 raw devices working 128K requests.
- The solution provides a high level of redundancy, allowing the parallel file system to keep its performance in case of a server failure.
During the PoC we had to simplify some parts of the solution
- No HA features. We don’t have a ready cluster software agent for xiRAID, but it can easily be implemented with a few scripts.
- We didn’t use spare servers for the PoC - doesn’t affect performance.
- We are using 3 NVMe drives from each EBOF per OST instead of 1 as would’ve been ideal.
- Each NVMe is split into 2 equal-sized namespaces to get to the required number of devices.